Philip J. Basford, Steven J. Johnston, Colin S. Perkins, Tony Garnock-Jones, Fung Po Tso, Dimitrios Pezaros, Robert Mullins, Eiko Yoneki, Jeremy Singer, and Simon J. Cox, (2019) Performance analysis of single board computer clusters. Future Generation Computer Systems. (doi:10.1016/j.future.2019.07.040).
Since the writing of that paper the Raspberry Pi 4 has been announced, meaning it could not be included in the main body of the text. Despite this we wanted to see how the changes introduced in the new version changed the available performance. The Raspberry Pi 4 is available in 4 different memory sizes, we purchased a 2GB varient so it is directly comparable to the Odroid C2.
The Raspberry Pi 4 Model B was then benchmarked used HPL and ATLAS compiled on the device as per the instructions on a previous blog post. To make sure that the Raspberry Pi did not overheat or enter CPU throttling mode a metal heatsink was attached to the CPU, and a 60mm fan was arranged to blow air over the surface of the Raspberry Pi. The Raspberry Pi was powered using an offical Raspberry Pi 4 USB-C power supply. Where the tests of the SBCs compared in the paper we performed on an isolated network the tests for the Raspberry Pi 4 were performed on the main university network which may have introduced a performance penalty.
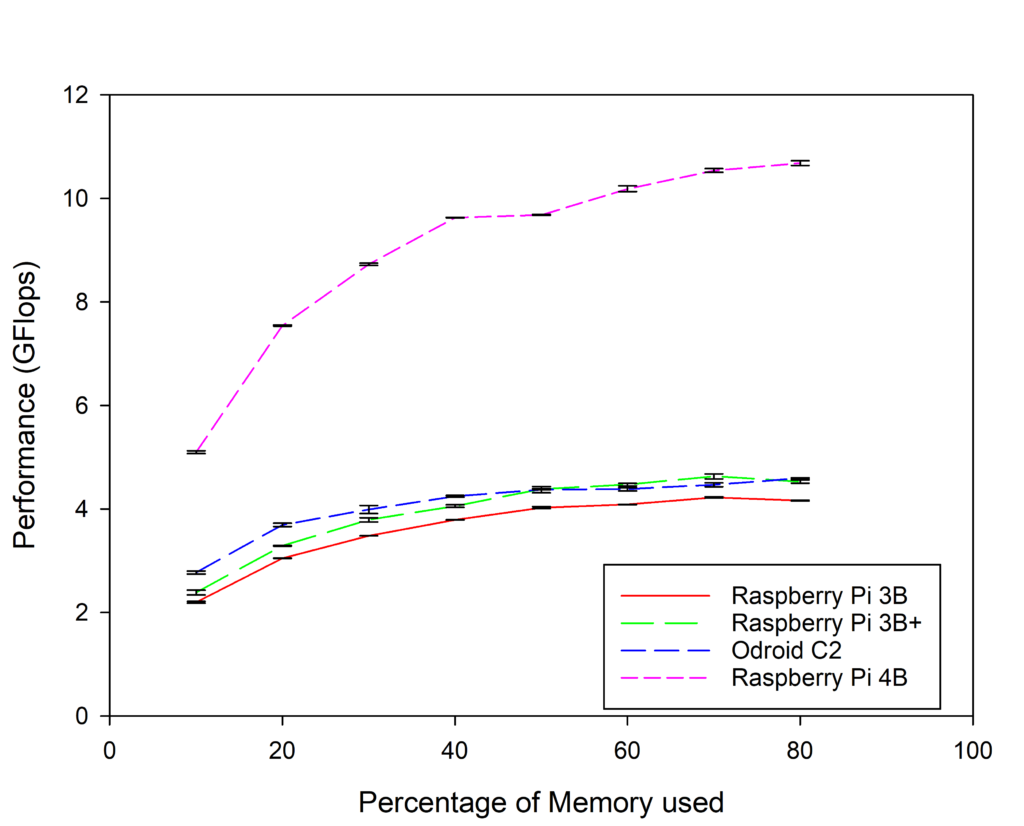
As can be seen in the chart the Raspberry Pi 4 significantly out performs the other SBCs at all problem sizes with a maximum of 10.68GFlops/s reached at 80% of RAM usage (swap disabled).
The initial testing of the Raspberry Pi 4 Model B shows that as a single node it has significantly better performance than any of the SBCs previously compared. It is hoped that as the network connection is capable of full gigabit/s speeds it will also scale better than the previous Raspberry Pi SBCs when combined into a cluster. For full details of the methodology used, and the performance of 16 node SBC clusters please read the published paper from doi:10.1016/j.future.2019.07.040 .
]]>- Install the dependencies
sudo apt install gfortran automake
2. Download atlas from https://sourceforge.net/projects/math-atlas/. At the time of writing this is version 3.10.3, your version might be different.
tar xjvf atlas3.10.3.tar.bz2
3. Create a directory to build in (it’s recommended to not build in the source hierarchy), and cd into it
mkdir atlas-build cd atlas-build/
4. Disable CPU throttling on the Pi – the process will not start if it detects throttling.
echo performance | sudo tee /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
This will stop throttling, I found it helped to have a fan blowing air over the CPU to make sure it didn’t over heat.
5. Configure and build Atlas. These steps will take a while. Do NOT use the -j flag to parallelize the make process, this will cause inconsistent results. Where possible it will run operations in parallel automatically.
../ATLAS/configure make
6. Download MPI and install
cd wget http://www.mpich.org/static/downloads/3.2/mpich-3.2.tar.gz tar xzvf mpich-3.2.tar.gz cd mpich-3.2 ./configure make -j 4 sudo make install
6. Download HPL from and extract configure
cd wget http://www.netlib.org/benchmark/hpl/hpl-2.2.tar.gz tar xzvf hpl-2.2.tar.gz cd hpl-2.2 cd setup sh make_generic cp Make.UNKNOWN ../Make.rpi cd ..
7. Then edit Make.rpi to reflect where things are installed. In our case the following lines are edited from the default. Note line numbers might change with future versions
ARCH = rpi
[…]
TOPdir = $(HOME)/hpl-2.2
[…]
MPdir = /usr/local MPinc = -I $(MPdir)/include MPlib = /usr/local/lib/libmpich.so
[…]
LAdir = /home/pi/atlas-build LAinc = LAlib = $(LAdir)/lib/libf77blas.a $(LAdir)/lib/libatlas.a
8. Then compile HPL
make arch=rpi
Congratulations. You should now have a working HPL install. Let’s test it.
9. Change into the working directory and create the configuration needed to test the system. As the pi has 4 cores you need to tell mpi to assign 4 tasks to the host. Depending on the ambient temperature you may need to add a fan to stop the Pi CPU overheating as these tests are very demanding.
cd bin/rpi cat << EOF > nodes-1pi localhost localhost localhost localhost EOF
Customise the HPL.dat input file. The file below is the starting point we use
HPLinpack benchmark input file Innovative Computing Laboratory, University of Tennessee HPL.out output file name (if any) 6 device out (6=stdout,7=stderr,file) 1 # of problems sizes (N) 5120 Ns 1 # of NBs 128 NBs 0 PMAP process mapping (0=Row-,1=Column-major) 1 # of process grids (P x Q) 2 Ps 2 Qs 16.0 threshold 1 # of panel fact 2 PFACTs (0=left, 1=Crout, 2=Right) 1 # of recursive stopping criterium 4 NBMINs (>= 1) 1 # of panels in recursion 2 NDIVs 1 # of recursive panel fact. 1 RFACTs (0=left, 1=Crout, 2=Right) 1 # of broadcast 1 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) 1 # of lookahead depth 1 DEPTHs (>=0) 2 SWAP (0=bin-exch,1=long,2=mix) 64 swapping threshold 0 L1 in (0=transposed,1=no-transposed) form 0 U in (0=transposed,1=no-transposed) form 1 Equilibration (0=no,1=yes) 8 memory alignment in double (> 0)
Run the test
mpiexec -f nodes-1pi ./xhpl
If all goes to plan your output should look similar to
================================================================================
HPLinpack 2.2 -- High-Performance Linpack benchmark -- February 24, 2016
Written by A. Petitet and R. Clint Whaley, Innovative Computing Laboratory, UTK
Modified by Piotr Luszczek, Innovative Computing Laboratory, UTK
Modified by Julien Langou, University of Colorado Denver
================================================================================
An explanation of the input/output parameters follows:
T/V : Wall time / encoded variant.
N : The order of the coefficient matrix A.
NB : The partitioning blocking factor.
P : The number of process rows.
Q : The number of process columns.
Time : Time in seconds to solve the linear system.
Gflops : Rate of execution for solving the linear system.
The following parameter values will be used:
N : 5120
NB : 128
PMAP : Row-major process mapping
P : 2
Q : 2
PFACT : Right
NBMIN : 4
NDIV : 2
RFACT : Crout
BCAST : 1ringM
DEPTH : 1
SWAP : Mix (threshold = 64)
L1 : transposed form
U : transposed form
EQUIL : yes
ALIGN : 8 double precision words
--------------------------------------------------------------------------------
- The matrix A is randomly generated for each test.
- The following scaled residual check will be computed:
||Ax-b||_oo / ( eps * ( || x ||_oo * || A ||_oo + || b ||_oo ) * N )
- The relative machine precision (eps) is taken to be 1.110223e-16
- Computational tests pass if scaled residuals are less than 16.0
================================================================================
T/V N NB P Q Time Gflops
--------------------------------------------------------------------------------
WR11C2R4 5120 128 2 2 25.11 3.565e+00
HPL_pdgesv() start time Wed May 16 10:35:46 2018
HPL_pdgesv() end time Wed May 16 10:36:11 2018
--------------------------------------------------------------------------------
||Ax-b||_oo/(eps*(||A||_oo*||x||_oo+||b||_oo)*N)= 0.2389736 ...... PASSED
================================================================================
Finished 1 tests with the following results:
1 tests completed and passed residual checks,
0 tests completed and failed residual checks,
0 tests skipped because of illegal input values.
--------------------------------------------------------------------------------
End of Tests.
================================================================================
The above steps were sufficient to get run atlas on a Pi 3B+ testing has shown that on a model 3B it may crash for N values above about 6000. This appears to be a problem with the hardware of the 3B, as described in a post on the pi forum. Following the step described in the post of adding the following line to /boot/config.txt enabled problem sizes up to and including 10240 to be executed.
over_voltage=2]]>