IRS: Interoperable Repository Statistics
A proposal to Activity
Area (iv) Pilot services of the Call
for Projects in the JISC Digital Repositories Programme (Circular 03/05).
Submitted by the University of Southampton, UK and Key Perspectives Ltd.
Supported by the University of Tasmania, Australia, Long Island University,
USA, and the COUNTER Project.
A. Introduction – A brief outline of the nature of the work to be undertaken, the length of the project, the proposed start date (June 2005) and a summary of how the project will contribute to the programme.
Programmes such as FAIR introduced repositories to many UK institutions. Now those institutional repositories (IRs) need to be filled with content. Internationally the signs are positive, with large organisations signing up to the recommendation of the recent Berlin 3 meeting in Southampton (http://www.eprints.org/berlin3/outcomes.html) to declare policies for IRs. With the prospective growth in content in IRs comes the need for more quantitative analysis and assessment: in short, a statistical analysis of usage. This is not derived from a need to monitor growth, though that will be a by-product, but to provide enhanced value services made possible by the growth.
IR usage statistics validated against recognised metrics are of particular relevance to activity area (iv) in this call where it is highlighted as 'contextual metadata', and would benefit five key stakeholders:
Authors: ability to monitor reader interest in their output and thence to influence future research decisions; encouragement to deposit new content
Searchers: additional context, and a filter mechanism, for the selection of material.
IR administrators: to assist planning decisions and justify the cost of IRs
Research funders and institutional research management: to assess the impact of funded work and to make future funding decisions
Service providers: could build quantitative pan-IR usage statistics services if consistent data is available from IRs via a well-defined server interface
'Usage statistics are the key metric in determining the value of electronic products and services. And they are an essential metric for both users and information providers.' (NFAIS Forum, October 2004 http://www.nfais.org/events/event_details.cfm?id=26).
The simplest approach would be for IRs to provide access to Web log usage data from the server, but this would produce incompatible data at different sites that would be hard to interpret, compare and aggregate in any meaningful way. If Web logs are to be the basis of such a service, the presentation and usage of such data needs to be standardised.
To create an effective research statistics service, an interoperable usage statistics mechanism must be developed for OAI-compliant repositories. This project will investigate the requirements for UK and international stakeholders (in the context of open access services being global) and build distribution and collection software for repositories as well as generic analysis and reporting tools. The project will design an application programming interface (API) for gathering download data, and implement this for data providers who are using common IR software.
On this basis, an OAI-like service provider could harvest and aggregate usage data from enabled IRs and other sources, such as subject repositories and journals. The project will build a pilot to demonstrate such a statistical analysis service provider. It is envisaged that data on usage of individual papers and collections could be returned to individual IRs, in an agreed and standardised format, for presentation. More specialised usage analysis services could in turn harvest from this service provider. As an example, data from the pilot service will be added to Citebase (http://citebase.eprints.org/), a citation impact service. It has been shown that for open access materials higher downloads correlate with higher citations (http://opcit.eprints.org/oacitation-biblio.html), so there is the potential to use download statistics as a predictor of impact.
All discussions of the requirements for usage statistics in digital library applications highlight the need for a coordinated, shared approach. This project will seek to validate and implement the findings through a specially-formed international consultative panel, including representatives of major archives, archive networks, developers of archive software, gateways and OAI service providers, as well as the chief OAI architects.
An obvious role model for providing statistical evidence of usage is COUNTER (Counting Online Usage of NeTworked Electronic Resources http://www.projectcounter.org/), which defines standards for reporting the use of e-journal contents. This model is powerful organisationally because it provides a framework in which reporting has been standardised across publishers and legitimised by both publishers and subscribers, and it offers a basis for auditing usage data from content providers. As far as peer reviewed papers are concerned, since copies deposited in IRs are intended as an open access supplement to the published version, it would be an advantage to be able to aggregate usage statistics of all versions of a paper, for example, linking usage of IR and journal versions.
The project will cover all OAI repositories, and measure usage of all types of materials within the repositories.
It is anticipated that standards for collection and presentation of usage data will be agreed and adopted by appropriate bodies through working with a standards-based organisation such as COUNTER and with the consultative panel.
Two of the partners in this project (Southampton, Les Carr; Tasmania, Arthur Sale) have begun to implement services to present statistics for established IRs, so have a practical knowledge of what is needed. The third partner, David Goodman of Long Island University, USA, is a member of the Project COUNTER Executive Committee, and brings experience of a similar approach to that proposed here, especially with regard to the need for consensus building across an industry. David has initiated an exercise to extend COUNTER to open access materials, including IRs, and this project would help fulfil that objective.
The partner seeking funding as part of this call by JISC is Southampton University. The University of Tasmania (possibly in collaboration with the National Library of Australia) will explore the possibility of complementary funding from the Australian Research Council, although this is unlikely to be available until late 2005 or 2006.
The project will last for 24 months from the programme start date in June 2005.
B. Project description – A description of the intended project plan, timetable and deliverables, risks, and an explanation of how the detailed project outcomes will be of value to the JISC community. Bidders should also include statements regarding IPR and sustainability issues.
Background
One of the factors motivating IRs is the potential efficiency gains in various parts of the scientific and scholarly publishing cycle: visibility, dissemination, use and impact. Researchers want their work disseminated and used, and need it to be cited. Institutions want to increase their visibility, and funders want to maximise the effect of their investments. Both citations and downloads are relevant evidence for the use of research, and many recent studies have shown that in a variety of communities, download figures for open access papers are strongly correlated with subsequent citations.
Current work by partners in the proposed project
Download statistics are already being collected by various repositories (e.g. in Tasmania and Southampton) and are processed and presented to the local community in various ways. For example, Figure 1a shows the abstract page for an eprint taken from the University of Tasmania repository, which runs Eprints (http://eprints.comp.utas.edu.au/). Access figures for the eprint are shown, and are broken down between the various countries of origin.
The software that has been written for the Tasmania project analyses the access log file of the repository and updates a mySQL database on a monthly basis. The software is available on an open-source licence and has been used by several universities. Work is in progress to port the software to a DSpace server at the University of Toronto.
By contrast, Figure 1b shows an extract from the summary page provided for the Southampton repository, showing one month's most popular downloads. This page is only used by repository staff and is not available publicly, even within the university, as there is no policy as to the value of such a 'league table'. A similar page is generated for the (currently independent) School of Electronics and Computer Science (ECS) repository, and this information is made available each term to its research committee as evidence of the effectiveness of the repository. It also demonstrates the impact of various news releases and marketing activities. (Similar publicly available ranked data is available from the Tasmania repository.)
|
a |
b |
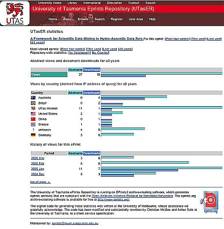

Figure 1. Download statistics are collected and presented in various ways: a, Public record: all views of a document broken down by country of access and month of access for an item in the University of Tasmania repository; b, Private record: monthly summary report of most popular downloads from the Southampton repository
Overall, there has been no consensus building yet among stakeholders over what data needs to be collected, what filtering mechanisms are appropriate, and what analyses are useful for academics in various disciplines.
Related work
Commercial concerns, especially in media and advertising, have driven the need for standards to measure usage of Web pages. In scholarly Web publishing similarly, commercial considerations, in particular the relationship between journal publishers and their primary customers, research libraries, have been the primary motivators for consensus on standards to measure, audit and report usage.
Statistics for e-journal usage
The most prominent development in e-journal usage statistics has been COUNTER, a cross-publisher group. COUNTER defines standards for reporting the use of electronic resources (in a digital library context), but its work is directed at journals, collections and publishers, rather than individual articles. More recent work addresses the reporting of data for individual items (books and reference works), but is still incompatible with an item-based open access distribution model where the concept of 'subscribers' is absent and a single server covers a large number of publication sources.
COUNTER is preparing to extend its reporting to include open access materials. David Goodman and Arthur Sale are working on a draft Code of Practice for IRs, and this will be extended to a standard for OA journals. A major problem is that COUNTER does not provide for the combination of data when usage from the same journal is obtained from different sources, even familiar sources such as Highwire and Ingenta. Libraries receive reports from each source, and must combine them locally. This approach becomes infeasible for OA material, and for different versions of material.
According to David Goodman: 'Even the publishers are interested (in IRs), wanting very much to have objective figures for how their articles are distributed.'
Initial OA COUNTER activity has therefore been a tentative step to see what (a) might be acceptable to institutions and their IRs, and (b) produce journal usage statistics
comparable to those of COUNTER. There has been no relative valuation.
Other projects to establish usage metrics within digital library contexts include: the ARL E-metrics project (http://www.arl.org/stats/newmeas/emetrics/) and the JISC NESLI 2 usage stats project, at UCE and Cranfield (http://www.ebase.uce.ac.uk/projects/NESLi2.htm).
Clients of these e-journal statistics projects are libraries. Compared with the needs of IRs, they have very different requirements: how much usage does a journal/collection get. IR managers and users want to know the usage of an individual paper, and to be able to view daily and by-site download patterns. Trend analyses of download data will be required. IR usage data will be used to find evidence of research quality, not just value-for-money data.
The developers of new Web journal publishing systems – such as Cornell's DPubS, Berkeley EPress (bepress) and, by virtue of being based on bepress, Proquest's Digital Commons –recognize the need to support usage statistics and provide data at the paper level. Through its association with Fedora at Cornell, it is claimed DPubS interoperates with software for IRs
Usage statistics for IRs
In comparison with journal publishing activities, support for gathering usage statistics for IRs has been patchy. The OSI report on IR software (http://www.soros.org/openaccess/software/) reveals that usage statistics are generated by DSpace and Fedora (among others), but that Fedora has no reporting tool built in.
Efforts to enhance the original log-analyser script that comes with DSpace have been made in Edinburgh's DStat. According to the developer Richard Jones, 'the original script was almost purely an aggregator: it simply counted actions performed and reported upon them. Later some more sophisticated aggregating features were added as well as embedding it into the DSpace UI and providing a relatively coherent time-based reporting process.' One limitation of DStat as a tool for log analysis is that it cannot link accesses to the metadata and full-text for the same item. In EPrints, the relationship is obvious just from manipulating the URLs. DStat can be viewed via a test server at http://banshee.lib.ed.ac.uk/dspace/statistics.
Distributed data: aggregator or gateway?
There is pressure to analyse referrals from 'gateways' as well as accesses from end-user institutions. An example is Australian Research Repositories Online to the World (ARROW http://www.arrow.edu.au/) which is planned to be a gateway to all Australian university repositories ('sources'). A gateway aggregates metadata but refers the searcher to the leaf repository for the actual document ('full-text'). For example, ARROW wants to know how many referrals reach its linked IRs compared to other access sources, and how many translate into full-text downloads.
An example of providing access and usage statistics for a distributed repository model is LogEc (http://logec.repec.org/), which reports data based on RePEc. This model highlights some of the issues that need to be investigated in gathering data for distributed services, such as an OAI model, in particular the aggregation of data. Aggregated data must include all usage of an item, ideally linking different instances of an item such as metadata and full-text, not just usage from a particular repository or service gateway.
In addition, account needs to be taken of access to repository items through the most common form of service, flat-file indexed search services such as Google. Evidentially, Google ranks the document (pdf) file higher than metadata pages (more textual context, also the desired target of the searcher from Google's perspective). EPrints and DSpace, for example, comply with Google's harvesting guidelines and Google indexes all pdfs as well as metadata pages.
Web server statistics are representations of the connections made to a server, and as such represent evidence of readers' activities and intentions as mediated by a complex distributed information service. Any Web log mining has to be aware of the Web infrastructure and services and understand the limitation of the interpretation that can be put on the data. In particular, models of user behaviour and server characteristics need to be taken into account.
What is needed
Two major issues to be tackled are:
it is essential to aggregate data from many IRs automatically to have enough data to be meaningful.
data comparable to publisher data (down to the journal level) must be provided.
The former requires definition of a harvesting interface, the writing of a harvester, and suitable aggregation/dissection software running on a global server. An early experimental statistics service that reports accesses from all Australian IRs and a few others has been developed at Tasmania (http://eprints.comp.utas.edu.au:81/cs/).
The results are reported in a journal report style as used by COUNTER, as an initial investigation of compatibility between the respective services. Aggregation has not yet been tackled, nor have the issues of journal identification in the presence of errors been addressed.
It is important to understand what statistics are important and useful to academics and researchers (in the various disciplines). For example, is it relevant if a paper is downloaded by another research institution rather than a home user? Should the downloads be weighted by the downloading institution? How should multiple downloads of the same document from the same institution be treated? What does it mean for a paper to be read by 30 different users? Should IRs try to set a cookie to track sessions? Should they ask for registration? Should there be a central registration service?
A harvesting model proposed
LogEc presents a harvesting solution and centralized analysis that is difficult to scale, since processing a significant log file takes minutes to hours. A pre-processing approach may scale more reasonably across the top 2000 institutions with repositories:
Each IR server runs a small cron job once per month, which reads the local log file and produces a summary log file (each line unchanged, just unimportant events deleted) in the public domain (or password protected, as preferred) which can be harvested by an analysis service. This reduces the log file to say 1% of its original size or less. The event discarding could be generous at first. Further reduction could be achieved by date-bracketing.
An analyser harvests the summary log files of registered IRs once per month (after summarization) and analyses them for a range of aggregated statistics.
Based on this approach the project will design an API for gathering the summary log files, and implement this for data providers who are using common IR software. An OAI-like service provider could harvest and aggregate usage data from enabled IRs and other sources, such as subject repositories and journals. The project will build a pilot to demonstrate such a statistical analysis service provider.
One of the important factors in this model is that if the retained log file entries are sufficiently comprehensive, then the means of analysis can be defined later and can indeed be flexible and evolve. No minimum standard for IRs is required, because the IRs do not produce the statistics, the global/national/discipline analyser does.
Consultative group: an international panel of major IR players
The above two sections highlight issues to be addressed and suggest some models as possible solutions to the need for IR download data. What this emphasises, especially if standards are to be accepted and adopted, is the need for cross-community consensus. With COUNTER as a major partner, we have identified many other key players and have begun to approach representatives of these organisations, as indicated below (where people are named, they have already agreed in principle to join this international consultative panel to tackle these issues; not all organisations listed had been formally approached prior to submission of this bid):
Major archives (CERN, Alberto Pepe; ArXiv; PubMed Central; CNRS, Laurent Romary)
Archive networks (Sherpa, Bill Hubbard; DARE, Leo Waaijers; RePEc)
Developers of archive software (DSpace Federation, Fedora)
Gateways (LogEc, Sune Karlsson, the manager of LogEc; Eprints UK; ARROW; DOAJ)
OAI service providers (OAIster, Kat Hagedorn; Citebase, Tim Brody)
Chief OAI architects (Herbert Van de Sompel, LANL)
Standards-maintaining organisations (COUNTER, David Goodman; OAI)
The role of this panel will be to determine and promote accepted practice with regard to harvesting and presentation of usage data for the contents of IRs, and to drive standards adoption through appropriate organisations. The preliminary invitations received the following comments:
Herbert Van de Sompel: 'With my LANL team, I am actively doing work on issues related to a harvesting framework for log data. Lots of issues involved.'
Leo Waaijers (DARE): 'The subject is of crucial importance, especially in relation to citations and impact factors.'
Jean-Yves Le Meur (CERN): 'we have done some (work) within CDS to count number of full text downloads and sharing/getting this information in a large IR context would be very useful.'
Laurent Romary (CNRS): 'I think that such a proposal is a very good idea and will contribute to even more collaboration between OA endeavours.'
Proposed activities and deliverables
- Stakeholder requirements analysis: what information do scientists and scholars want about the use to which their work is being put? What analyses do their managers want to perform? This work to be scoped and performed by Key Perspectives Ltd, a consultancy specialising in such studies, and consisting of qualitative (small group discussions and interviews with stakeholders) and quantitative (web-based questionnaire) analyses to establish evidence for the direction of subsequent activities.
- Establish consultative group and agree agenda; progress possible standards adoption
- Design generic API for gathering download data from IRs with pre-filtering to eliminate effect of crawlers and anomalous download behaviours (e.g. individuals downloading or mirroring collections of material).
- Implement API for common IR platforms: Eprints, DSpace, RePEc, etc.
- Build pilot statistics analysis service: implement
best practice Web log mining techniques and publicly document them.
analyses and visualisations that are the outcome of (1)
- Integrate statistics analysis with IRs. Repositories themselves should be able to download them for incorporation into their own repositories/Web sites.
- Add usage data to Citebase for citation-indexed papers.
- Test and debug technical services.
- Project evaluation, by Key Perspectives Ltd.
- Dissemination and advocacy. Tell the community of IRs about the resulting services and show how to adopt them. Promote standards adoption via COUNTER and consultative panel
Risks
One risk for this project could be a lack of content across IRs to be the basis of meaningful measurements. This risk affects all IR service providers, but is less likely to affect this project because the provision of download data seems to be one of the first requirements of institutions setting up IRs. It is argued that the provision of quantitative services will play an important role in motivating new IRs and underpinning the commitment of institutions and authors to these IRs, an important factor in building content.
The other key risk is that of participation by a minimal number of IRs. Since aggregation of data is important, such failure would mean that the project could not demonstrate its value. This risk will be tackled through the network of OA providers, and the consultative panel.
In terms of turning the requirements analysis into prospective standards, it is possible that there may be no consensus among the consultative panel. The possibility can be minimised by not attempting to build one all-embracing standard, but by identifying a series of standards that might be recognised within key constituencies.
Intellectual Property Rights
The project raises no IPR issues. Software developments are planned to be open source and will be available for integration in all IR platform software. Prospective open standards will be handed over to appropriate organisations, such as COUNTER and OAI, for maintenance and development. It is expected the consultative committee will play a key role in identifying appropriate standards partners and to facilitate handovers, or even to evolve as a formal entity itself beyond the project to adopt and promote the standards.
Privacy
The project has a potential privacy issue, in that the presentation of data will probably need to identify the source of an access in an aggregated fashion (e.g. to the university level). Raw access logs may contain the IP address of the user, and institutions may be reluctant (a) to provide information about their enquirers to the service, and (b) to expose their institutional usage data for scrutiny by others. Part (a) will be tackled at the harvesting level, but part (b) will depend on the attitudes of institutions, funding bodies and the community.
Sustainability
The outputs of the project – software and standards – are intended to be self-sustaining within the communities that might wish to maintain, develop and apply them, as identified above.
Project management
The project will have a part-time (0.4 FTE) project manager throughout, to coordinate efforts with partners and the consultant, and manage internal (Southampton) development. Crucially, this project manager will be responsible for setting up and initially directing the consultative panel, with a view to the panel becoming self-directing. Advocacy and dissemination will be handled by the project manager, who will also report to JISC and be responsible for ensuring that the project meets JISC requirements.
Evaluation
The project will be will be evaluated by Key Perspectives Ltd in terms of the major deliverables (standards for harvestable usage data for collection and presentation), services (API in IRs and software; pilot statistics service provider), and overall project outcomes for the community.
Dissemination
This will be a high profile project in the OA, IR and OAI communities. All main partners will be active in reporting the work of the project. We anticipate they would want to promote the successes of the project through their own news sources. ECS at Southampton now has a dedicated Marketing and Communications Manager, who can help in identifying stories for the press where appropriate. The School of Computing at the University of Tasmania has a similar appointment to help promote the activity within Australia.
Given the emphasis on collaboration, there is further dissemination channels, especially through members of the consultative panel and organizations with authority in this field such as COUNTER and the Open Archives Initiative.
Two open workshops will be held in different locations in the UK towards the end of the project to promote awareness, implementation and use of the new software and services.
A Web site would be created for the project. Southampton has a number of sites in the eprints.org domain that provide related Web outlets. Dissemination plans include presenting reports on the project at international conferences.
Management and steering
A management group, with one or more members from each of the three main partners, will direct the project. Given the wide geographical spread of partners the management group will communicate electronically and meet quarterly by telecon or videocon to review progress, ensure plans are achieved or updated as necessary, and to maintain a focus on the timely availability of deliverables. The international consultative group will perform a steering role.
Timetable
|
Q1 |
Q2 |
Q3 |
Q4 |
Q5 |
Q6 |
Q7 |
Q8 |
|
|
Project management (inc. manage consultative panel) |
||||||||
|
1 Stakeholder requirements analysis |
||||||||
|
2 Establish and drive consultative panel |
||||||||
|
3 Design generic API |
||||||||
|
4 Implement API for common IR platforms |
||||||||
|
5 Build pilot statistics analysis service |
||||||||
|
6 Integrate statistics analysis with IRs |
||||||||
|
7 Build into Citebase |
||||||||
|
8 Test and evaluate technical services |
||||||||
|
9 Project evaluation |
||||||||
|
10 Dissemination and advocacy |
C. Budget – A summary of the proposed budget which in broad outline identifies how funds will be spent over the life of the project,
The project has resourcing for 0.4 Project Manager, 1 Programmer and a 4 months of a Consultant.
D. Key personnel – Names and brief career details of staff expected to contribute to the project, including qualifications and experience in the area of work proposed and evidence of any projects of similar nature successfully completed. Clearly indicate when posts will need to be advertised.
Dr Leslie Carr, School of Electronics and Computer Science, Southampton University, Principal Investigator, lac@ecs.soton.ac.uk, http://www.ecs.soton.ac.uk/~lac/
Leslie is a Senior Lecturer in the IAM Group at Southampton University. He is PI for the current JISC Preserv project, and director of Eprints software development. He is also Southampton technical director for the eBank project, phase II (JISC 2005-2006), as he was previously for the Open Citation Project (JISC-NSF, 1999-2002), both of which have informed the development of Eprints. Leslie is a member of the OAI technical committee.
School of Electronics and Computer Science, Southampton University, posts to be advertised:
1.0 FTE software developer
0.4 FTE project manager
Key Perspectives Ltd, Truro, UK a.swan@talk21.com
Key Perspectives has previously produced reports for JISC, based on extensive surveys, identifying a number of critical findings on user and author behaviours with respect to IRs.
Professor Arthur Sale, School of Computing, University of Tasmania, Australia Arthur.Sale@utas.edu.au, http://www.comp.utas.edu.au/app/staff_profile.jsp?user=ahjs
Arthur holds the Chair of Computing (Research) at the University of Tasmania, and is Research Coordinator of the School of Computing. Previously the University's Pro Vice-Chancellor, he took up this position in 2000 to develop the impact of research in the University's ICT schools. The University's eprint repository is due to his work, and has resulted in several other Australian universities establishing IRs or modifying their IR operations (e.g. Melbourne, Bond). Arthur has also been active in two major projects funded by the Australian Government: ARROW and Australian Digital Theses Program, and in international OA activities.
Dr David Goodman, Long Island University, USA, and a member of the Project COUNTER Executive Committee, david.goodman@liu.edu, see http://palmer.cwpost.liu.edu/faculty.html
Professor Stevan Harnad, School of Electronics and Computer Science, Southampton University, harnad@ecs.soton.ac.uk, http://www.ecs.soton.ac.uk/~harnad/, and Centre de Neuroscience de la Cognition (CNC), University du Quebec a Montreal
One of the leading promoters of open access, Stevan has been the principal driver of work to measure the growth and impact of IRs, many of which are based on EPrints software, which he initiated. As PI for the Open Citation Project (JISC-NSF, 1999-2002), Stevan led the development of Citebase, one of the first services to quantify the impact of an open access archive, and subsequently identified the correlation between downloads and citations. Stevan continues to advocate the need for further quantitative work to promote the role of IRs, as emphasised by the Institutional Archives Registry.