Challenge
Start of topic | Skip to actions
Provenance Challenge: University of Manchester, School of Computer Science
- Provenance Challenge: University of Manchester, School of Computer Science
- Slideset presented at the Amsterdam meeting, June 11, 2009:
- Workflow representation
- Open Provenance Model Output
- SPARQL queries
- A note of Taverna provenance queries
- Complete OPM graph
- Query 1 For a given detection, which CSV files contributed to it?
- Query 2: "Was the range check (IsMatchTableColumnRanges) performed for this table?"
- Query 3: Which operation executions were strictly necessary for the Image table to contain a particular (non-computed) value?
- Notes on the IDs used in the graph, and on the values of artifacts:
- Query Results
- Suggested Workflow Variants
- Suggested Queries
- Suggestions for Modification of the Open Provenance Model
- Conclusions
Team and Project Details
- Participant names: Paolo Missier
Slideset presented at the Amsterdam meeting, June 11, 2009:
Workflow representation
The PAN-STARRS workflow is defined as a sequence of steps with exit conditions. While this is naturally expressed using an imperative language, the Taverna workflow model is that of a dataflow, i.e., the entire workflow execution is data-driven and there are (essentially) no control structures. This makes the implementation of the PAN-STARRS workflow less than obvious, in that, for example, one cannot simply "halt" a workflow in response to a data error condition. Taverna's treatment of data errors involves propagating the error from the point it is generated, through the remaining dataflow graph. Errors are treated just like any other piece of data, but can be distinguished as representing an error condition. Thus, the workflow continues to execute, but the workflow controller prevents Taverna processors (i.e., workflow tasks) from executing when any of the inputs are errors, immediately returning the same error values instead. Thus, the overall behaviour is that of a dataflow where errors are spotted, but they do not have the effect to halt executions. In my rendering of the challenge workflow I provide one boolean output for each possible error condition. In addition, error values appear in the provenance trace as "error values". All intermediate Taverna values are identified using URIs, of the form "t2:ref//dataref.taverna.org?- Taverna version of the challenge workflow (PNG):
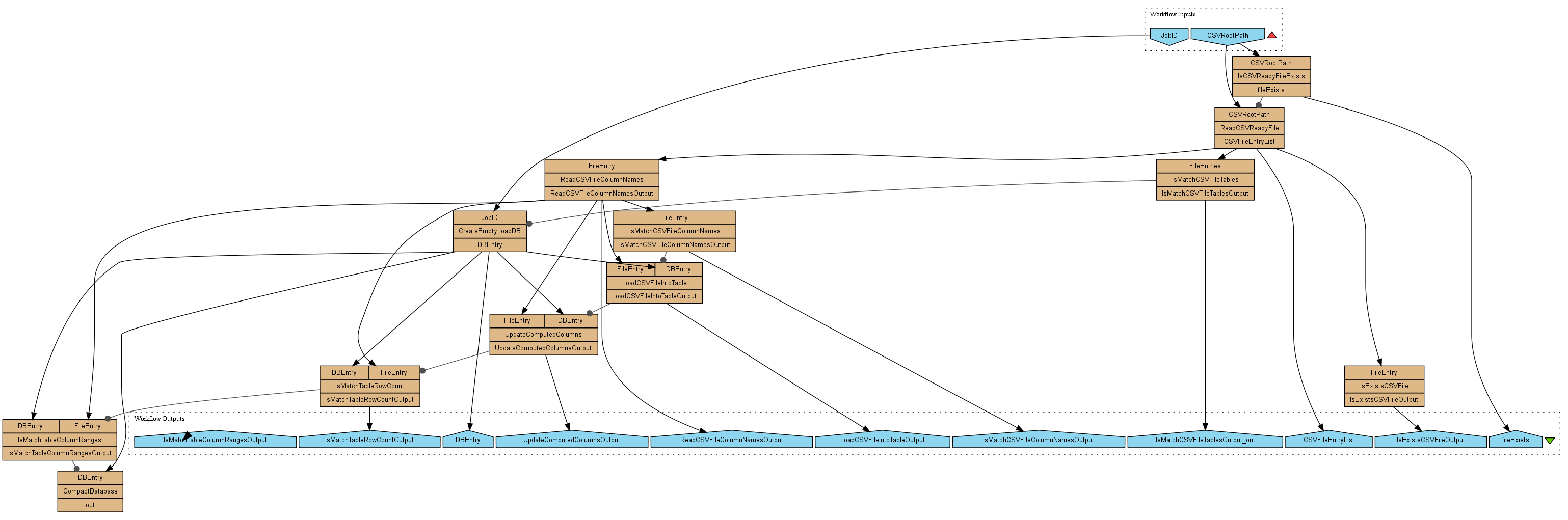
- PAN-STARRSTaverna.svg: Taverna version of the challenge workflow (SVG)
Open Provenance Model Output
The output is in RDF and is produced using the Tupelo provenance API, courtesy of Joe Futrelle at NCSA. The OPM graphs below, in RDF/XML format, represent (1) the complete OPM graph (the result of the "fully unfocused query" alluded to above), and (2,3,4) for each of the first 3 provenance queries, a graph that contains enough information to answer the query, but does not include parts of the graph that are not relevant for the query. This is done to show how the queries can be answered by Taverna on its native provenance system, and the resulting subgraphs are then exported to OPM.SPARQL queries
Below are a few simple utility SPARQL queries that may be useful to inspect the OPM RDF graph:- allArtifacts.sparql: List all artifacts
- allProcesses.sparql: List all processes
- WhoUsedWhat.sparql: List Who Used What (with roles)
- WhoWasGeneratedByWhom.sparql: List Who Generated What (with roles)
- processesAndIterations.sparql: List all iterations for all processes
A note of Taverna provenance queries
A provenance query in Taverna consists of two parts:- a set of ports (output processor variables) whose provenance we are interested in. Optionally, one can also specify an iteration step, i.e., when the value is a list whose elements are produced during iterations. We refer to these using the notation:
- a set of target processors, where we want provenance to be reported. This is done to avoid unnecessary noise in the query answer, i.e., we "jump" over uninteresting processors. We refer to these using the notation:
Complete OPM graph
- OPMGraph-complete.rdf: Complete provenance graph (RDF/XML) for one successful run of the PAN-STARRS workflow
- OPMGraph-complete.xml: Complete provenance graph (XML) for one successful run of the PAN-STARRS workflow
- OPMGraph-complete.dot: Complete provenance graph (dot) for one successful run of the PAN-STARRS workflow
- Complete provenance graph (PNG) for one successful run of the PAN-STARRS workflow:

Query 1 For a given detection, which CSV files contributed to it?
note this will be updated to reflect Paul's latest qualification of the purpose of the query. This maps to the Taverna provenance query:- OPMGraph-query1.xml: Provenance graph (XML) as an answer to provenance query 1
- OPMGraph-query1.dot: Provenance graph (dot) as an answer to provenance query 1
- OPMGraph-query1.rdf: Provenance graph (RDF) as an answer to provenance query 1
- Provenance graph (PNG) as an answer to provenance query 1:
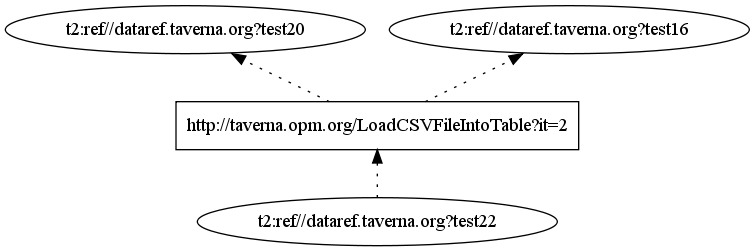
------------------------------------------------------------------------------------------------------------------------------------------------------ | artifact | value | ====================================================================================================================================================== | <t2:ref//dataref.taverna.org?test20> | "J062941_LoadDB" | | <t2:ref//dataref.taverna.org?test21> | "true" | | <t2:ref//dataref.taverna.org?test15> | "/Users/paolo/Documents/myGRID/OPM/PC3/SampleData/J062941/P2_J062941_B001_P2fits0_20081115_P2Detection.csv" | ------------------------------------------------------------------------------------------------------------------------------------------------------where the third entry is file that contributes to the detection. One can inspect the Used relations:
-------------------------------------------------------------------------------------------------------------------------------------------------------- | process | usedArtifact | role | processIteration | ======================================================================================================================================================== | "http://taverna.opm.org/LoadCSVFileIntoTable?it=2" | "t2:ref//dataref.taverna.org?test15" | "LoadCSVFileIntoTable/FileEntry?it=2" | "[2]" | --------------------------------------------------------------------------------------------------------------------------------------------------------
Query 2: "Was the range check (IsMatchTableColumnRanges?) performed for this table?"
this translates simply into a boolean query that tests whether IsMatchTableColumnRanges? is mentioned anywhere in the provenance graph, and is basically a reacheability query: target = TOP / ALL / ALL --all output ports of the top level workflow select = IsMatchTableColumnRanges?- OPMGraph-query2.xml: Provenance graph (XML) as an answer to provenance query 2
- OPMGraph-query2.dot: Provenance graph (dot) as an answer to provenance query 2
- OPMGraph-query2.rdf: Provenance graph (RDF) as an answer to provenance query 2
- Provenance graph (PNG) as an answer to provenance query 2:

Query 3: Which operation executions were strictly necessary for the Image table to contain a particular (non-computed) value?
Taverna can only provide the simple answer to the query, because query answers are based purely on the data dependencies that are exposed to the workflow. This translates in Taverna by considering that the Image table is populated from the 2nd CSV file. Since the provenance graph only mentions processors that contributed to the execution, a query that traces back from the target port any processor collects all required processors along the path: target = TOP / LoadCSVFileIntoTableOutput? / 1 select = ALL- OPMGraph-query3.xml: Provenance graph (XML) as an answer to provenance query 3
- OPMGraph-query3.dot: Provenance graph (dot) as an answer to provenance query 3
- OPMGraph-query3.rdf: Provenance graph (RDF) as an answer to provenance query 3
- Provenance graph (PNG) as an answer to provenance query 3:
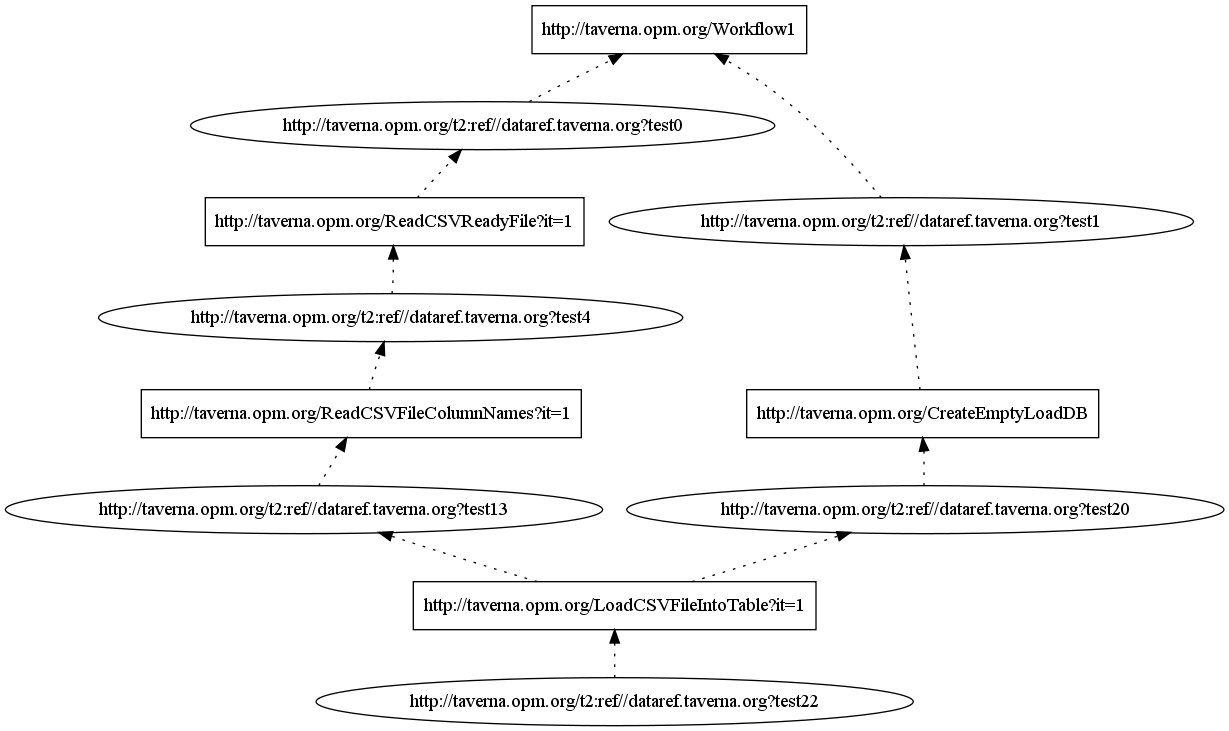
Notes on the IDs used in the graph, and on the values of artifacts:
In Taverna, repeated invocation of a processor occurs when the processor expects an atomic value, i.e., a string, but instead its input port is bound to a list of strings (the story is actually a bit longer but this will suffice for this note). So for example, processor LoadCSVFileIntoTable? is defined to have one input port, called DBEntry, which expects a string (the file name). In this workflow it receives a list of 3 file names. This causes it to execute independently on each of them. A trace for each of these 3 independent executions appears in the OPM graph, and each occurrence is indexed as [0], [1], and [2]. (This path notation makes it possible to express more complex paths into nested lists). Since there is no explicit provision in OPM to account for indexing of multiple occurrences of the same process, one new ID is created for each occurrence simply by appending the index to the process name. So for example, the following records appear in the list produced by WhoUsedWhat.sparql:-------------------------------------------------------------------------------------------------------------------------------------------------------- | process | usedArtifact | role | processIteration | ======================================================================================================================================================== | "http://taverna.opm.org/LoadCSVFileIntoTable?it=2" | "t2:ref//dataref.taverna.org?test16" | "LoadCSVFileIntoTable/FileEntry?it=2" | "[2]" | | "http://taverna.opm.org/LoadCSVFileIntoTable?it=1" | "t2:ref//dataref.taverna.org?test14" | "LoadCSVFileIntoTable/FileEntry?it=1" | "[1]" | | "http://taverna.opm.org/LoadCSVFileIntoTable?it=0" | "t2:ref//dataref.taverna.org?test12" | "LoadCSVFileIntoTable/FileEntry?it=0" | "[0]" | --------------------------------------------------------------------------------------------------------------------------------------------------------This is interpreted as "occurrence [i] of LoadCSVFileIntoTable used artifact t2:ref//dataref.taverna.org?test16 with role LoadCSVFileIntoTable/FileEntry?it=i during iteration _[i]_" The last item, processIteration, is added as an explicit RDF triple to the Used resource to make it possible to query the graph by iteration. Note also that the role is used, at the moment, to describe the binding of a variable to a value (an artifact ID), e.g. LoadCSVFileIntoTable/FileEntry?it=0 means that t2:ref//dataref.taverna.org?test20 is the artifact (id) bound to variable FileEntry of processor LoadCSVFileIntoTable during iteration [0]. Regarding values, at the moment my implementation can optionally include a
Query Results
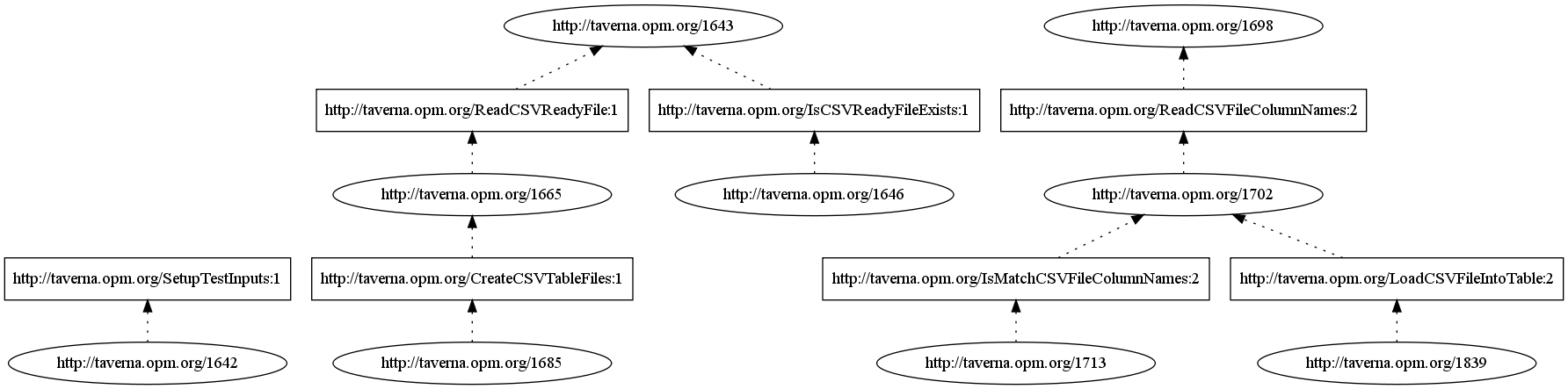
This section describes how third party OPM graphs are imported into the Taverna provenance model. Once imported, the challenge queries can be answered using the Taverna provenance query engine, just like the native Taverna provenance traces.Representing third party OPM graphs in the Taverna provenance model: the MPOD idea
One peculiarity of the Taverna provenance model is that it relies on the structure of the static workflow graph in order to answer provenance queries efficiently. This is not a problem when provenance is captured from a Taverna workflow execution, of course, but it may become problematic when third party OPM graphs are imported, because those do not carry the original workflow structure. Our solution is to use the causal relations provided by the graph, to "induce" a Minimal Plausible Originating (Taverna) Dataflow (MPOD) that could have produced the graph. As a consequence, the import algorithm consists of two parts:- generate a MPOD from the artifact-artifact and artifact-process relations, and store it in the provenance DB. This includes processors with inputs and output ports, connected through data dependencies. A small number of mapping rules are used for this purpose;
- generate the bindings of ports to artifacts that would have been observed upon execution of the generated workflow.
| source | OPM file | MOPD visualization(where available) |
| UC Davis | Halts at IsCSVReadyFileExists | |
|---|---|---|
| UC Davis | Success |  |
| Soton | 2 accounts | |
| NCSA | 609241_output.xml |  |
Suggested Workflow Variants
Suggested Queries
Suggestions for Modification of the Open Provenance Model
Conclusions
-- PaoloMissier - 07 May 2009to top
| I | Attachment  | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| | OPMGraph.rdf | manage | 62.9 K | 07 May 2009 - 14:43 | PaoloMissier | Complete provenance graph for one successful run of the PAN-STARRS workflow |
| | PAN-STARRSTaverna.png | manage | 222.5 K | 30 Apr 2009 - 15:15 | PaoloMissier | Taverna version of the challenge workflow (PNG) |
| | PAN-STARRSTaverna.svg | manage | 30.1 K | 30 Apr 2009 - 15:16 | PaoloMissier | Taverna version of the challenge workflow (SVG) |
| | allArtifacts.sparql | manage | 0.4 K | 07 May 2009 - 15:45 | PaoloMissier | List all artifacts |
| | allProcesses.sparql | manage | 0.3 K | 30 Apr 2009 - 15:36 | PaoloMissier | List all processes |
| | WhoUsedWhat.sparql | manage | 0.7 K | 30 Apr 2009 - 15:37 | PaoloMissier | List Who Used What (with roles) |
| | WhoWasGeneratedByWhom.sparql | manage | 0.7 K | 30 Apr 2009 - 15:37 | PaoloMissier | List Who Generated What (with roles) |
| | processesAndIterations.sparql | manage | 0.4 K | 30 Apr 2009 - 15:37 | PaoloMissier | List all iterations for all processes |
| | OPMGraph-query1.rdf | manage | 2.9 K | 14 May 2009 - 15:56 | PaoloMissier | Provenance graph (RDF) as an answer to provenance query 1 |
| | OPMGraph-query2.rdf | manage | 7.9 K | 14 May 2009 - 16:05 | PaoloMissier | Provenance graph (RDF) as an answer to provenance query 2 |
| | OPMGraph-query3.rdf | manage | 8.7 K | 14 May 2009 - 16:09 | PaoloMissier | Provenance graph (RDF) as an answer to provenance query 3 |
| | OPMGraph-complete.rdf | manage | 51.9 K | 14 May 2009 - 15:47 | PaoloMissier | Complete provenance graph (RDF/XML) for one successful run of the PAN-STARRS workflow |
| | OPMGraph-complete.xml | manage | 33.4 K | 14 May 2009 - 15:48 | PaoloMissier | Complete provenance graph (XML) for one successful run of the PAN-STARRS workflow |
| | OPMGraph-complete.dot | manage | 15.1 K | 14 May 2009 - 15:48 | PaoloMissier | Complete provenance graph (dot) for one successful run of the PAN-STARRS workflow |
| | OPMGraph-complete.png | manage | 233.7 K | 14 May 2009 - 15:48 | PaoloMissier | Complete provenance graph (PNG) for one successful run of the PAN-STARRS workflow |
| | OPMGraph-query1.png | manage | 22.2 K | 14 May 2009 - 15:55 | PaoloMissier | Provenance graph (PNG) as an answer to provenance query 1 |
| | OPMGraph-query1.xml | manage | 2.4 K | 14 May 2009 - 15:56 | PaoloMissier | Provenance graph (XML) as an answer to provenance query 1 |
| | OPMGraph-query1.dot | manage | 0.8 K | 14 May 2009 - 15:56 | PaoloMissier | Provenance graph (dot) as an answer to provenance query 1 |
| | OPMGraph-query2.png | manage | 37.6 K | 14 May 2009 - 16:04 | PaoloMissier | Provenance graph (PNG) as an answer to provenance query 2 |
| | OPMGraph-query2.xml | manage | 5.5 K | 14 May 2009 - 16:04 | PaoloMissier | Provenance graph (XML) as an answer to provenance query 2 |
| | OPMGraph-query2.dot | manage | 2.3 K | 14 May 2009 - 16:05 | PaoloMissier | Provenance graph (dot) as an answer to provenance query 2 |
| | OPMGraph-query3.png | manage | 75.9 K | 09 Jun 2009 - 13:19 | PaoloMissier | OPM graph for query 3 from native 2 PAN-STARRS |
| | OPMGraph-query3.xml | manage | 6.0 K | 14 May 2009 - 16:09 | PaoloMissier | Provenance graph (XML) as an answer to provenance query 3 |
| | OPMGraph-query3.dot | manage | 2.5 K | 14 May 2009 - 16:09 | PaoloMissier | Provenance graph (dot) as an answer to provenance query 3 |
| | MOPD_OPMDefaultAccount-1525f737-2d11-4a0f-a897-ea9fec09951b.png | manage | 100.3 K | 08 Jun 2009 - 11:20 | PaoloMissier | MOPD for UC Davis |
| | MOPD_OPMDefaultAccount-4acaef59-c25b-4a7d-9f99-499c290ee378.png | manage | 112.1 K | 08 Jun 2009 - 11:28 | PaoloMissier | MOPD for NCSA |
| | ImportedOPMGraph-query3.png | manage | 58.4 K | 08 Jun 2009 - 20:54 | PaoloMissier | query3 |
| | PC3-report.pdf | manage | 735.0 K | 12 Jun 2009 - 07:26 | PaoloMissier | PC3 report presented at OPM PC3 meeting |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach image or document | Printable version | Raw text | More topic actions
Revisions: | r1.13 | > | r1.12 | > | r1.11 | Total page history | Backlinks
Revisions: | r1.13 | > | r1.12 | > | r1.11 | Total page history | Backlinks