The Provenance Architecture
The Provenance Architecture is defined as a computer system that deals with all issues pertaining to the recording, maintenance, visualisation, reasoning and analysis of the documentation of the process that underpins the notion of provenance. Such a system is a software implementation of the Open Provenance Architecture, which identifies the different roles in such a system, their interactions and the kind of provenance representation they are expected to support.
As far as the architecture is concerned, we distinguish the activity that consists of recording the representation of provenance of some data from the activity that makes use of a recorded provenance representation. We now further detail our notion of "documentation of a process", and we describe the architecture for recording it and making use of it.
Provenance Representation
In this section, we introduce the key elements that form the representation of provenance in a SOA; further refinement will ultimately lead to data types for provenance representation. In our discussion, given the provenance of some data, we shall make the distinction between the whole of provenance and one of its constituents, i.e., a specific piece of information documenting part of the process that led to the data. Hence, a given element of the provenance representation will be referred to as a p-assertions (assertion, by an actor, pertaining to provenance). We note that a given p-assertion may belong to the provenance representation of multiple pieces of data. A p-assertion that is recorded documents a step of a process in progress, which ultimately will lead to a piece of data. At the time of the recording, we may ignore the piece of data that will be produced; however, the p-assertion being recorded constitutes an element of the provenance representation of the data. For instance, when some quality wood is being transported in the Amazon forest, one may ignore that it will be used for creating the frame for a future famous painting, still to be painted.
Computer science has a long tradition of focusing on communications and interactions as a central concept used in the study and modelling of complex systems, e.g., programming languages semantics, process algebrae and more recently in biological systems models. In the context of SOAs, interactions consist of the messages exchanged between actors. By capturing all the interactions that take place between actors involved in the computation of some data, one can replay an execution, analyse it, verify its validity or compare it with another execution. Given the open nature of the distributed systems that we consider, interactions (i.e., message exchanges) are the only events that we can observe. Hence, describing such interactions is core to the documentation of process.
Therefore, the documentation of a process that leads to a piece of data includes a set of interaction p-assertions, each describing an interaction between actors involved in the computation of the data. Practically, an interaction p-assertion contains a message exchanged between two actors.
Interaction p-assertions capture the observable interactions between actors of a system. In some circumstances, however, actors' internal states may also be necessary to understand the functionality, performance or accuracy of actors, and therefore the nature of the result they compute. Hence, we introduce the notion of an actor state p-assertion as the documentation provided by an actor about its internal state in the context of a specific interaction. Actor state documentation is extremely varied: it can include the function the actor performs, the workflow that is being executed, the amount of disk and CPU a service used in a computation, the floating point precision of the results it produced, or application-specific state descriptions. We note that in a distributed system, an actor state is not externally observable, and therefore can only be captured by cooperative contribution of the actor itself.
In summary, p-asssertions can be of two disjoint kinds: interaction p-assertions and actor state p-assertions. We note that both interaction and actor state p-assertions are independent of the actual service technology used to implement applications.
Provenance Architecture Roles
In order to support the capture and querying of these categories of provenance, we have specified a provenance architecture that takes into account a broad range of use cases. It is summarised in the figure below, which we now discuss.
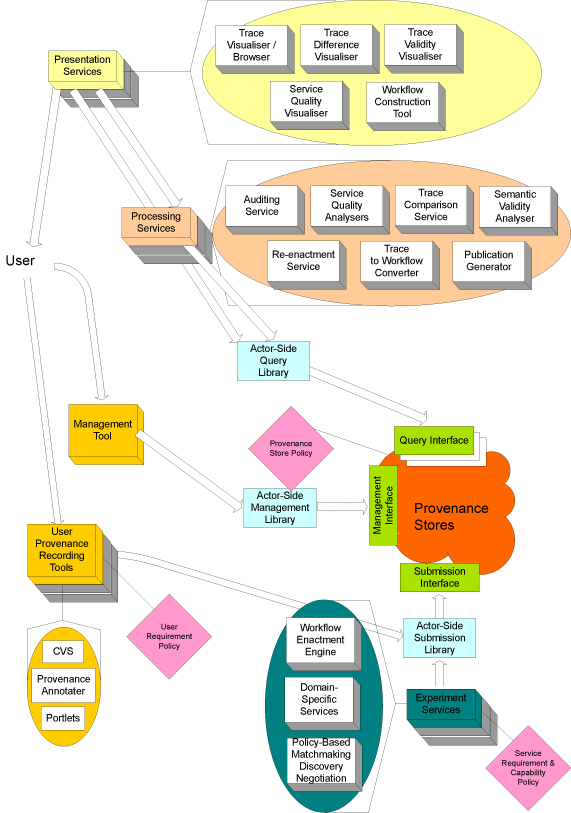
Central to the architecture is the notion of a provenance store, which is designed to store and maintain provenance representation beyond the life of a Grid application. In a given application, one or more provenance stores may be used in order to archive the representation of provenance: multiple provenance stores may be required for scalability reasons or for dealing with the physical deployment of a given application, possibly involving firewalls.
In order to accumulate p-assertions, a provenance store provides a submission interface that allows different actors to submit p-assertions related to their interactions and internal states. A provenance store is not just a sink for p-assertions: it must also support some query facility that allows, in its simplest form, browsing of its contents, and, in its more complex form, search, analysis and reasoning over the provenance representation so as to support use cases. To this end, we introduce query interfaces that offer multiple levels of query capability. Finally, since provenance stores need to be configured and managed, an appropriate management interface is introduced.
Some actor-side libraries facilitate the tasks of submitting p-assertions in a secure, scalable and coherent manner and of querying and managing provenance stores. They are also designed to ease integration with legacy applications. Interfaces and libraries have different purposes: the former specify the messages accepted and returned by provenance stores, and will be the focus of a standardisation proposal to ensure that applications can inter-operate with different implementations of provenance stores; the latter are convenience libraries offering bindings for specific programming languages.
During an application's execution, all application services are expected to submit p-assertions to a provenance store; this not only applies to domain-specific services, but also to workflow enactment engines and registries. Additionally, users may have access to tools to manage provenance stores and to submit information to provenance stores, such as annotations about previous execution.
Once p-assertions have been recorded in a provenance store, provenance representation can be used by processing services and presentation services. The former provide added-value to the query interfaces by further searching, analysing and reasoning over recorded provenance, whereas the latter essentially visualise the contents of the store and of processing services' outputs. The figure provides examples of such processing and presentation services offering functionality. For instance, processing services can offer auditing facilities, can analyse quality of service based on previous execution, can compare the processes used to produce several data items, can verify that a given execution was semantically valid, can identify points in the execution where results are no longer up-to-date in order to resume execution from these points, can re-construct a workflow from an execution trace, or can generate a textual description of an execution. Presentation services can for instance offer browsing facilities over provenance stores, visualise differences in different execution, illustrate execution from a more semantic viewpoint, can visualise the performance of execution, and can be used to construct provenance-based workflows. We note that such a list of processing and presentation services is illustrative and not exhaustive; furthermore, it does not represent a commitment by the project to deliver these services specifically.
Finally, to be generic, a provenance architecture must be deployable in many different contexts and has to support user preferences. To adapt the behaviour of the architecture to the prevailing circumstances and preferences, several policies are introduced to help configure the system in its different aspects. Specifically,
-
policies state user requirements about recording, e.g., to identify the provenance stores to use, the level of documentation required by the user, desired security aspects;
policies specify capabilities of documenting execution that services may wish to advertise (such as their ability to provide some type of actor states documentation), but in order to fulfill these, that they may also require from other services they rely upon (such as their need for high throughput or highly persistent provenance stores);
policies define configurations of provenance stores, from a deployment and security viewpoint (e.g., resources they use, their access control list, or registry where they should be advertised). By making explicit all these policies, it becomes possible to discover services that match user or other service needs. When requested policies conflict with discovered policies, negotiation can be initiated to find a compromise between the offer and demand.
A complete description of the Provenance Architecture is available here.