An Introduction to HPC
Definition of HPC
No strict definition but any compute system delivering over 1
Gigaflop/s; alternatively, any computer that has an order of magnitude,
or greater, performance than current top-end workstations.
The need for HPC
Areas suitable for application are:
- large scientific, engineering, and medical applications.
- business and commerce are applying financial modelling techniques.
- database applications for fast retrieval of large quantities of data.
- Virtual Reality.
Why the parallel approach?
To get higher performance from contemporary sequential computers
requires: • Increasingly sophisticated chip design, which requires
complex memory hierarchy and multiple functional units.
This is expensive!!
Economic issues
There are only about at most 200 sales of supercomputers world wide per year.
So must leverage chip design for PC's and workstations.
Parallel Processing
Technological and economic constraints on single processor computers has
driven the approach towards parallel computation. This is more
cost-effective - in terms of hardware - since commodity state-of-the-art
chips may be used. The major features of parallel computers are:
- Processors can perform operations simultaneously.
- An interconnection network that allows processors to cooperate and
share data.
Machine Classification
Here we do not classify according to the structure of the machine, but
rather on how the machine relates its instructions to data being
processed.
MIMD (Multiple Instruction, Multiple Data)
- Tightly coupled - shared memory e.g. SG PowerChallenge, Sun SPARCserver 1000.
- Loosely coupled - distributed memory e.g. Meiko CS-2, IBM SP-2, Cray T3D
- Workstation cluster - e.g. Local Area Networks (LANs) and Wide Area Networks (WANs) running, say, PVM or MPI.
SIMD (Single Instruction, Multiple Data)
MasPar MP-2, Thinking Machine's CM-2, and others.
MIMD systems
In these systems:
- Different processors can execute different instructions at the same time.
- There is no central controller, any synchronization is achieved through software or specialized hardware.
MIMD - tightly coupled
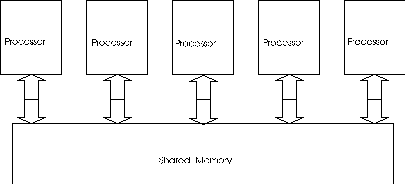
In shared memory systems:
- At least part of the memory is shared between processors.
- Hardware and operating system designed to assure that multiple
processors do not erroneously write to the same address simultaneously
and so corrupt memory contents.
- Interprocessor communication is possible through reservation of
memory locations (usually control blocks) visible to all processes.
- May not scale well for large numbers of processors due to memory
contention bottleneck.
Examples: SG PowerChallenge, Sun SPARCserver 1000.
MIMD - loosely coupled
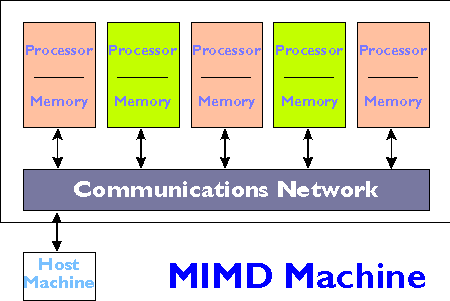
In distributed memory systems:
- Each processor or node has its own local memory.
- Communication between processors is achieved by sending messages using
library calls.
- Scaling to much larger number of nodes is possible while still
maintaining system balance.
Examples: Meiko CS-2, IBM SP-2, Thinking Machine's CM-5, and Cray T3D.
MIMD - workstation cluster

In these distributed memory systems:
- Each processor or node may be any compute resource on a LAN or WAN.
- Communication is achieved through exchange of data, using message
passing library calls e.g. PVM, MPI, and others.
- Scaling to much larger number of nodes is possible while still
maintaining system balance.
Example: CERN HP workstation cluster for High Energy Physics event processing.
SIMD systems
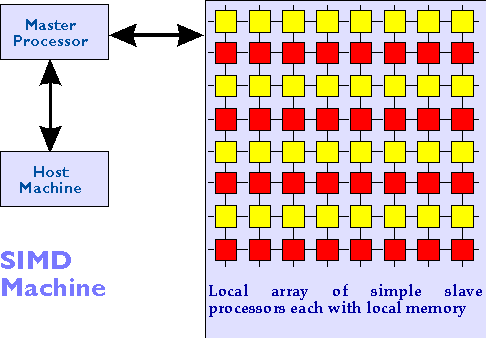
In these systems:
- All processors execute the same instruction at the same time.
- Each processor has its own local memory, and communicates with other
processors using special instructions.
Examples include Thinking Machines CM-2, and MasPar MP-2.
Interconnections
Mechanisms for communication between processors is provided by:
- Point-to-point - a dedicated connection between two processors.
- Buses - several processors physically sharing a common path.
Physical Node topologies
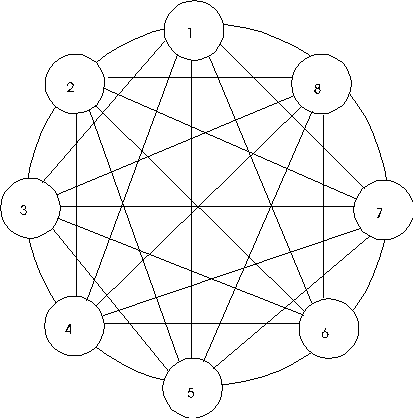
Processors or nodes may be connected in a variety of topologies. These include:
- Connect each node to every other node; example, BBN Butterfly.
- Connect each node to its neighbour in a ring.
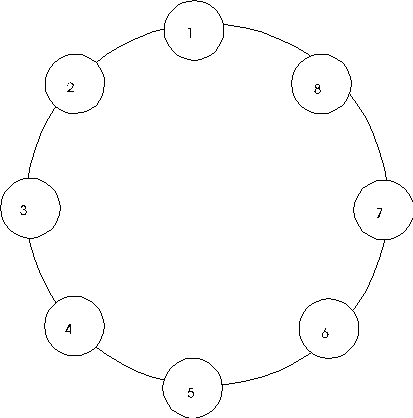
- Lattice in two or three dimensions; example, Cray T3D.
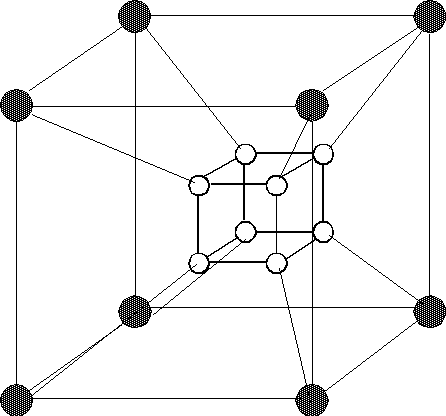
- Hypercube; example, n-Cube range.
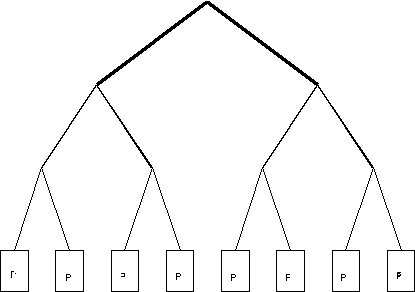
- Fat tree; example Thinking Machine's CM-5.
A non-computing example of High Performance processing
Construction of a wall. This illustrates:
- Domain decomposition - dividing the problem (of building the wall)
between processors (bricklayers).
- Size of the domain will determine speedup.
- Communication at boundaries.
- Difficulties encountered in irregular domains (load balancing).
Summary of different types of parallelism in constructing the wall
The construction of the wall also illustrates different forms of
parallelism found in computing.
- Data parallelism. This is when all bricklayers are working on a
different section of wall, but essentially performing the same task.

- Pipelining. This was shown when the task of building the wall was
decomposed into horizontal sections.

- Task parallelism. Although this was not illustrated we can envisage
construction of the wall by assigning different tasks to different
workers. For instance, one worker may be delivering bricks, another
mixing cement, and another laying the bricks.



Submitted by Mark Johnston,
last updated on 9 November 1994.