
|
What is an Open Journal? |
Important note. While the background and philosophy discussed here remain relevant to the project, the technical implementation has been completely redesigned since this seminar, with the emphasis on server-side link processing rather than requiring a client-based plug-in.
 The hypertext guru Ted Nel son said, in effect, that electronic
information without links is dead information. Hardly any scholarly journals
that have recently arrived on the Web have hypertext links. Given the task
of bringing established journals online, it would be fairer to say that
such journals have not yet had the chance to come alive. The Open Journal
project is changing that.
The hypertext guru Ted Nel son said, in effect, that electronic
information without links is dead information. Hardly any scholarly journals
that have recently arrived on the Web have hypertext links. Given the task
of bringing established journals online, it would be fairer to say that
such journals have not yet had the chance to come alive. The Open Journal
project is changing that.
 The key feature of online information is speed of access. Bush
could forsee the power of an information system where any item of information
can be retrieved at the speed with which we create thought associations.
Through the combination of the Web and large numbers of links we are approaching
the critical point for realising this capability, following which we will
enter a new dimension where we use and respond to information in new ways.
The key feature of online information is speed of access. Bush
could forsee the power of an information system where any item of information
can be retrieved at the speed with which we create thought associations.
Through the combination of the Web and large numbers of links we are approaching
the critical point for realising this capability, following which we will
enter a new dimension where we use and respond to information in new ways.
 As used in this context, open derives from a technical term
which refers to the ability of types of software or different applications
to work together, to interoperate. The effect of an open approach to
online multimedia is to support connections, implemented with links, between
the inevitable proliferation of formats that support the various digital
media. By separating the link data rather than integrating it within native
formats enables the connection, or link, framework to act independently
of the content applications, by whomever and with whatever software the
content was produced. For publishing applications, for example, the advantages
of this are clear.
As used in this context, open derives from a technical term
which refers to the ability of types of software or different applications
to work together, to interoperate. The effect of an open approach to
online multimedia is to support connections, implemented with links, between
the inevitable proliferation of formats that support the various digital
media. By separating the link data rather than integrating it within native
formats enables the connection, or link, framework to act independently
of the content applications, by whomever and with whatever software the
content was produced. For publishing applications, for example, the advantages
of this are clear.
 An Open Journal could encompass a set of papers from a conventional
journal, or a larger collection of documents such as an e-print archive.
Ultimately it is likely that new structures will emerge, structures that
will be created by content publishers or link publishers, by other intermediaries
such as libraries, or by readers. There will be greater cross-linking between
products, journal titles for example, that in the paper model are seen
as distinct entities. Instead, an Open Journal structure is defined by
the particular link service context that is chosen. Consider a scenario:
every paper journal in a given field, say biology, could be glued together.
Then any reader can tear out the articles that do not interest them and
retain those that do in one handy volume. This is one way to envisage the
flexibility and customisability of an open journal provided by link services.
An Open Journal could encompass a set of papers from a conventional
journal, or a larger collection of documents such as an e-print archive.
Ultimately it is likely that new structures will emerge, structures that
will be created by content publishers or link publishers, by other intermediaries
such as libraries, or by readers. There will be greater cross-linking between
products, journal titles for example, that in the paper model are seen
as distinct entities. Instead, an Open Journal structure is defined by
the particular link service context that is chosen. Consider a scenario:
every paper journal in a given field, say biology, could be glued together.
Then any reader can tear out the articles that do not interest them and
retain those that do in one handy volume. This is one way to envisage the
flexibility and customisability of an open journal provided by link services.
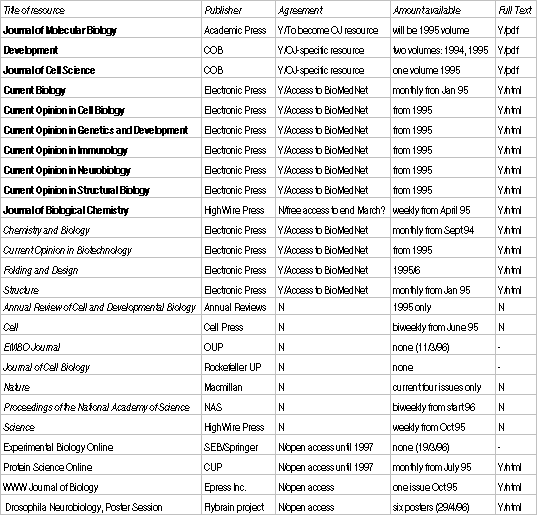
This is one possible view of an open journal, in this case the projects Open Journal in biology, which links full-text journals in html and Adobe Acrobat, journal abstracts from citation services and publishers home pages, graphical databases of molecular structures, and an online dictionary service. Some of this material is accessible through an arrangement with the publishers; some requires no special permission at all. In this spreadsheet are just a few of the available resources for this biology Open Journal, and this is the view of just one user. It can also be seen that within this selection there are different degrees of highlighting of titles indicating further preferences of this user for must-see journals (bold) and of-some-interest journals (italics). The actual extent of this users open journal could be tailored between these extremes through the link service.
NOTE. This spreadsheet view is for illustrative purposes only, and plays no role in the open journal technology.
 The link service is made available to the user through two icon
buttons on the far left of the title bar of the Web browser window. The
first button shows the available link actions: the straightforward follow
link, creating new links using start link and end link, show links
(which are not always visible as blue buttons), and compile links, which
adds links to the viewed document from the chosen link database, or linkbase,
and makes the links visible.
The link service is made available to the user through two icon
buttons on the far left of the title bar of the Web browser window. The
first button shows the available link actions: the straightforward follow
link, creating new links using start link and end link, show links
(which are not always visible as blue buttons), and compile links, which
adds links to the viewed document from the chosen link database, or linkbase,
and makes the links visible.
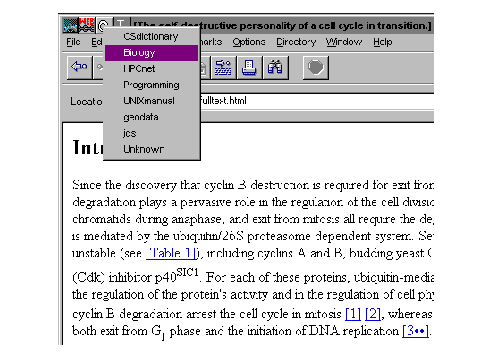 Of more importance here, since we are discussing a journal-like
collection of documents, is the Context menu, through which a given set
of links can be chosen by the user. The sorts of contexts that could be
available might be my journal, or Proc. Roy. Soc. (if you are the Royal
Society! or subscribe to its link service, say) or, as this case, biology.
Remember, choosing the link context selects a particular set of stored
links. The customisability derives from the fact that what is stored is
a set of pointers, not the original documents.
Of more importance here, since we are discussing a journal-like
collection of documents, is the Context menu, through which a given set
of links can be chosen by the user. The sorts of contexts that could be
available might be my journal, or Proc. Roy. Soc. (if you are the Royal
Society! or subscribe to its link service, say) or, as this case, biology.
Remember, choosing the link context selects a particular set of stored
links. The customisability derives from the fact that what is stored is
a set of pointers, not the original documents.
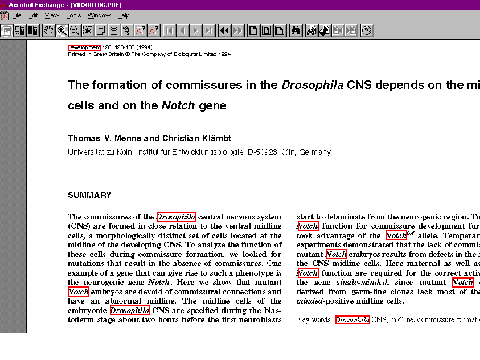 The above examples illustrate the application of the link service to html
documents, but links can also be added to documents produced in the popular
Adobe Acrobat application, as shown here. This facillity is provided by
plug-in applications written by the Electronic Publishing group at Nottingham
University.
The above examples illustrate the application of the link service to html
documents, but links can also be added to documents produced in the popular
Adobe Acrobat application, as shown here. This facillity is provided by
plug-in applications written by the Electronic Publishing group at Nottingham
University.
 Despite the huge information space it has generated, ease of
access to information, through links and the now commercialised search
services, is what has made the Web so popular, but it lacks a means to
provide an overview of a collection of documents. The Open Journal document
managemnt system builds on familiar contents list structures with the facility
to add new interactive applications such as Java to, for example, monitor
the Web dynamically and update the list as necessary. Again, the unique
new feature of an Open Journal is the application of a link service to
provide order, improve navigation and act as an information filter.
Despite the huge information space it has generated, ease of
access to information, through links and the now commercialised search
services, is what has made the Web so popular, but it lacks a means to
provide an overview of a collection of documents. The Open Journal document
managemnt system builds on familiar contents list structures with the facility
to add new interactive applications such as Java to, for example, monitor
the Web dynamically and update the list as necessary. Again, the unique
new feature of an Open Journal is the application of a link service to
provide order, improve navigation and act as an information filter.
 Although links are characteristic of the Web, these features
are a significant enhancement of its linking capabilities and are achieved
through the use of a managed link service such as the Distributed Link
Service. In particular, note the feature that will be vital to link publishers,
the ability to link from other peoples data; and the link automation
feature of a generic link. Any word or phrase that has been used to create
a generic link will link to a chosen document or set of documents from
whichever document that word or phrase is viewed. This works, for example,
for documents that have been published after the generic link has
been created.
Although links are characteristic of the Web, these features
are a significant enhancement of its linking capabilities and are achieved
through the use of a managed link service such as the Distributed Link
Service. In particular, note the feature that will be vital to link publishers,
the ability to link from other peoples data; and the link automation
feature of a generic link. Any word or phrase that has been used to create
a generic link will link to a chosen document or set of documents from
whichever document that word or phrase is viewed. This works, for example,
for documents that have been published after the generic link has
been created.
What does all this mean for publishing? Here are two differing views. See the accompanying viewpoint papers for more detailed presentations of these two models. Draw your own conclusions.


