Challenge
Start of topic | Skip to actions
Second Provenance Challenge Template
Participating Team
- Short team name: OntoGrid
- Participant names: Jose Manuel Gomez-Perez, Francisco Javier García (iSOCO), Rafael González-Cabero (UPM), Chris Van Aart (Y'All)
- Project URL: http://www.ontogrid.net
- Slides on the knowledge-oriented provenance environment, used during the Second Provenance Challenge workshop (June 26th 2007, Monterey Ca): KOPE-2ndProvenanceChallenge.ppt
OntoGrid Approach Overview
According to the myGrid provenance pyramid, we can structure provenance information as a pyramid with four main levels: Data, Organization, Process, and Knowledge. The first three levels have been widely addressed in the available literature and in the first edition of the Challenge. Thus, our focus is primarly on the Knowledge level. Knowledge provenance, settled on top of the provenance pyramid, is focused on the interpretation of the information registered by the other three. This is the first participation of OntoGrid in the Provenance Challenge. We aim at semantically interpreting the process documentation recorded by third party provenance systems by means of knowledge representation techniques from the field of Semantic Web that help users unacquainted with provenance systems to understand the results of a provenance query and therefore the execution of a distributed process. Our provenance interpretation system is compliant with the provenance datamodel of the University of Southampton. OntoGrid's distributed process documentation technology, accordingly to the S-OGSA architecture, the Business Process Monitor (BPM), records process documentation in a format compliant with such datamodel. We intend to use BPM as the infrastructure for documenting processes in distributed environments. BPM also provides a series of inspection methods which allow querying such process documentation. More information about BPM can be obtained in http://www.insurancegrid.org/bpm/ (click on "About"). Our approach to analysing past processes through their provenance logs is based on ProblemSolvingMethods (PSMs). A PSM is defined as a sequence of actions that accomplish a task in a specific domain. PSM have been traditionally used in Artificial Intelligence as a tool to model, establish, and control the sequence of actions required to solve domain-specific tasks by means of decomposing them into simpler subtasks down to the level of primitive actions. Beyond execution of a reasoning process, PSM can also be used to analyze computational problem-solving behavior or reasoning in a service-oriented scenario. In this regard, PSM are high-level, domain-independent, knowledge templates that explain the underlying reasoning going on within a process execution. Our aim is to interpret provenance data (logs) at the knowledge level of the provenance pyramid, using the PSM analytic approach. Our provenance system detects occurrences of PSM amidst process documentation resulting from the execution of a particular task. There are two different approaches towards using PSM for knowledge provenance. On the one hand, domain-independent PSM describing different reasoning processes, like those identified in CommonKADS, e.g. validation, monitoring, or diagnostics, can be used to come up with a description, in terms of the particular domain of application, of the reasoning process which has taken place during execution. On the other hand, domain-level (instead of reasoning-level), process-oriented PSM can be used to specify the knowledge flow of distributed applications and validate their execution by means of interpreting their provenance logs against such specification. In the case of the Challenge, we have followed the first approach in its simpler flavour: we use a single, domain-independent PSM category which describes a Catalogation reasoning process to interpret, in terms of the population-based brain atlases domain, the execution of the Challenge workflow as recorded by preexisting process documentation infrastructure.Provenance Data for Workflow Parts
Interpretation of provenance in a given domain requires a number of knowledge resources which, in the case of the Challenge, are the following:- The OntoGrid PSM meta-model (psmontology.rdfs). It describes the basic entities of a PSM, and how they are related with each other. These key components can be found in the ProblemSolvingMethods section and are represented as follows:
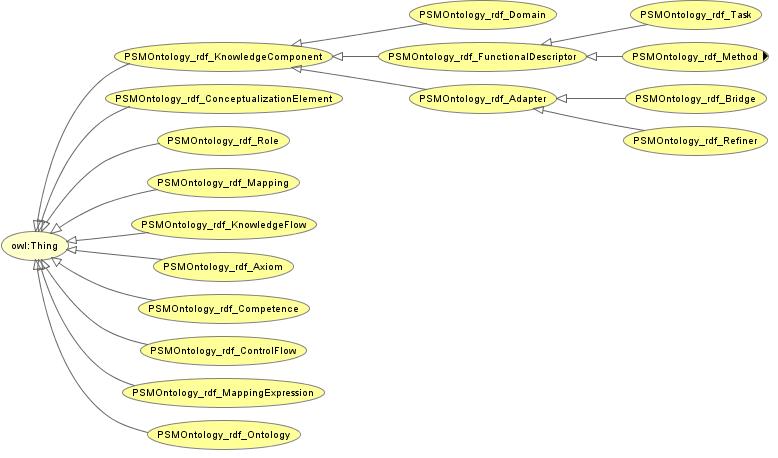
- The catalogation PSM library (psmontologyModel.rdf) which provides a hierarchy of methods describing strategies to solve catalogation tasks. This PSM library is an instance of the OntoGrid PSM meta-model.
- The Brain Atlas ontology (BrainAtlasDomainOntology.rdfs, BrainAtlasDomainOntology.rdf). It describes the domain to be interpreted by the PSM library.
- ChallengeProvenanceLog.xml: Semantically-enhanced provenance log for the population-based brain atlas workflow
![]()
- AlgorithmResult.xml: XML structure representing the PSM hierarchy and their enriched roles resulting from the provenance interpretation process using PSM.
- Stage1-2.xml: Part 1: align_warp and reslice (stages 1 and 2)
- Stage3.xml: Part 2: softmean (stage 3)
- Stage4-5.xml: Part 3: slicer and convert (stages 4 and 5)
Model Integration Results
The provenance interpretation approach uses process documentation produced accordingly to the provenance datamodel of the University of Southampton. The provenance to be interpreted with our PMS libraries is obtained by means of provenance queries, using the pre-existing querying facilities.Translation Details
The semantically-enhanced provenance log of the brain atlas workflow has been processed in order to produce an explicit representation of the p-DAG. This pre-processing eases the matching process between (in this case) the Catalogation PSM library and the Brain Atlas p-DAG, which is the core of the provenance interpretation based on PSM. The resulting structure simplifies creating XPath queries against the p-DAG XML, which relate PSM input and output role sets.Benchmarks
Describe your proposed benchmark queries, how the comparable quantities are determined, and the results of applying the benchmark to your own system Our approach to provenance interpretation is not focused on querying provenance but rather on interpreting, i.e. explaining, distributed process executions by the provenance information returned by pre-existing provenance query facilities. Thus, it is orthogonal to any system compliant with the University of Southampton datamodel. Thus, benhmarking can not appeal to its querying capabilities (as they are the same of the underlying provenance infrastructure) but rather to the quantity, i.e. does the system detect all the expected occurrences of the available PSM in the provenance logs?, and quality of the intepretations produced, i.e. do they contribute for a better understanding of process executions by non-provenance knowledgeable users?Further Comments
Provide here further comments.Conclusions
Provide here your conclusions on the challenge, and issues that you like to see discussed at a face to face meeting. -- SimonMiles - 11 Dec 2006 -- JoseManuel - 28 May 2007to top
| I | Attachment  | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| | psmontology.rdfs | manage | 5.6 K | 25 May 2007 - 13:28 | JoseManuel | PSM meta-model |
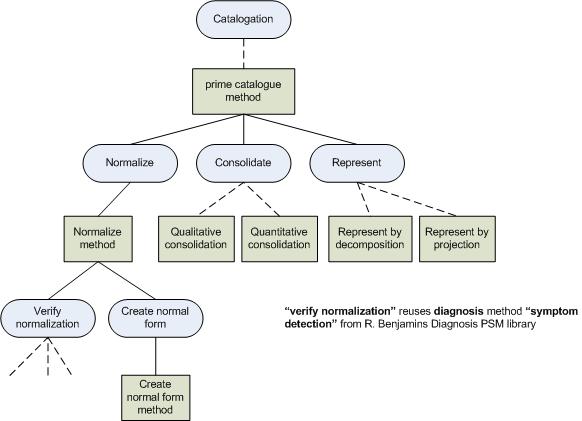
| | catalogation_task-method_decomposition.jpg | manage | 26.5 K | 27 May 2007 - 12:28 | JoseManuel | Task-Method decomposition of a generic catalogation task |
| | primecataloguemethod.jpg | manage | 9.8 K | 27 May 2007 - 12:47 | JoseManuel | Prime catalogue method |
| | BrainAtlasDomainOntology.rdfs | manage | 3.9 K | 27 May 2007 - 15:47 | JoseManuel | Brain Atlas domain ontology schema |
| | BrainAtlasDomainOntology.rdf | manage | 11.7 K | 27 May 2007 - 15:48 | JoseManuel | Brain Atlas domain ontology |
| | psmontologyModel.rdf | manage | 34.0 K | 27 May 2007 - 16:10 | JoseManuel | Catalogation PSM library |
| | psmontologyModel.jpg | manage | 45.2 K | 27 May 2007 - 16:24 | JoseManuel | PSM meta-model |
| | ChallengeLog.xml | manage | 87.6 K | 27 May 2007 - 17:54 | JoseManuel | Semantically-enhanced provenance log for the population-based brain atlas workflow |
| | AlgorithmResult.xml | manage | 5.2 K | 28 May 2007 - 08:20 | JoseManuel | XML structure representing the PSM hierarchy and their enriched roles |
| | ChallengeProvenanceLog.xml | manage | 87.7 K | 28 May 2007 - 08:19 | JoseManuel | Semantically-enhanced provenance log for the population-based brain atlas workflow |
| | Stage1-2.xml | manage | 43.2 K | 28 May 2007 - 14:51 | JoseManuel | Part 1: align_warp and reslice (stages 1 and 2) |
| | Stage3.xml | manage | 31.1 K | 28 May 2007 - 14:52 | JoseManuel | Part 2: softmean (stage 3) |
| | Stage4-5.xml | manage | 29.6 K | 28 May 2007 - 14:52 | JoseManuel | Part 3: slicer and convert (stages 4 and 5) |
| | KOPE-2ndProvenanceChallenge.ppt | manage | 925.0 K | 28 Jun 2007 - 15:49 | JoseManuel | Slides on the knowledge-oriented provenance environment used during the presentation at the Second Provenance Challenge (June 26th 2007, Monterey Ca) |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach image or document | Printable version | Raw text | More topic actions
Revisions: | r1.14 | > | r1.13 | > | r1.12 | Total page history | Backlinks
Revisions: | r1.14 | > | r1.13 | > | r1.12 | Total page history | Backlinks