Challenge
Start of topic | Skip to actions
Second Provenance Challenge Template
Participating Team
- Short team name: SDG
- Participant names: Karen Schuchardt, Tara Gibson, Eric Stephan
- Project URL: http://sdg.pnl.gov
- Reference to first challenge results (if participated): SDG
Differences from First Challenge
For the second challenge, we have modified our provenance repository so that it is an Alfresco content management system modified to support the URIQA for getting, putting, and deleting rdf triples. Alfresco provides management of content, but in our modified version, metadata and provenance is managed through a Sesame RDF store. The extensible DASL search interface has been modified to take SPARQL queries. Our data model is unchanged with the following exceptions:- real namespaces are now used
- rdf type is defined
Provenance Data for Workflow Parts
Data Model Description We assign unique ids to resources we want to describe. Currently the ids are simply generated urls. RDF is then used to describe the resources, which for the provenance challenge include: workflow instances, actor instances, data port instances, and parameter instances. The workflow execution graph is captured primarily through the links isInput and hasOuput. The naming is somewhat inconsistent in form because the names reflect links that flow in a single direction. A naming convention such as hasInput and hasOutput is more clear but more difficult to generate the graph. Important link properties are shown in italics in the table. The data model (also shown graphically in http://twiki.pasoa.ecs.soton.ac.uk/pub/Challenge/SDG2/provmodel.tif)| Name | Description | Applies |
|---|---|---|
| dc:title | a non-unique identifying name for some resource | all |
| dc:format | a type identifying the content/type of a resource | all |
| rdf:type | ontological categorization | all |
| dc:creator | identifier for person responsible for creating the workflow | workflow |
| sdg:creaed | date/time of creation | workflow |
| sdg:wasRunBy | identifier for person who ran the workflow | workflow |
| sdg:owningInstitution | name of organization responsible for workfow | workfow |
| sdg:hasStatus | value of workflow execution status | workflow |
| sdg:instantiationOf | Currently referes to the name of class of object for which this resource is an instantiation. In fullsystem, would be link to the resource | workflow, actor |
| sdg:startedExectuion | date/time at which execution started | workflow, actor |
| sdg:finishedExecution | date/time at which execution complted | workflow, actor |
| sdg:hasParameter | link to resource that fully describes a parameter instance | actor |
| sdg:hasOuput | link to resource that fully describes a data (port) output | actor |
| sdg:isInput | link to resource that receives this resoruce as input | parameter, data |
| sdg:isPartOf | link to workflow instance that the resource is associated with (grouping mechanism) | actor, data, parameter |
| sdg:hasSource | link to workflow sources (actors with no inputs) | workflow |
| sdg:value | optional value of data item | data, parameter |
| sdg:hasHashOfValue | optional hash of value of data | data, parameter |
- http://twiki.pasoa.ecs.soton.ac.uk/pub/Challenge/SDG2/stage1-final.xml (Stage 1)
- http://twiki.pasoa.ecs.soton.ac.uk/pub/Challenge/SDG2/stage2-final.xml (Stage 2)
- http://twiki.pasoa.ecs.soton.ac.uk/pub/Challenge/SDG2/stage3-final.xml (Stage 3)
- http://twiki.pasoa.ecs.soton.ac.uk/pub/Challenge/SDG2/q7-stage1-final.xml (Stage 1)
- http://twiki.pasoa.ecs.soton.ac.uk/pub/Challenge/SDG2/q7-stage2-final.xml (Stage 2)
- http://twiki.pasoa.ecs.soton.ac.uk/pub/Challenge/SDG2/q7-stage3-final.xml (Stage 3)
- stage1-pnl.owl
- stage2-pnl.owl
- stage3-pnl.owl
- sdg-provenance.owl : New Data Model
Model Integration Results
We translated and performed the queries over data from Mindswap and VisTrails Vistrails Query1: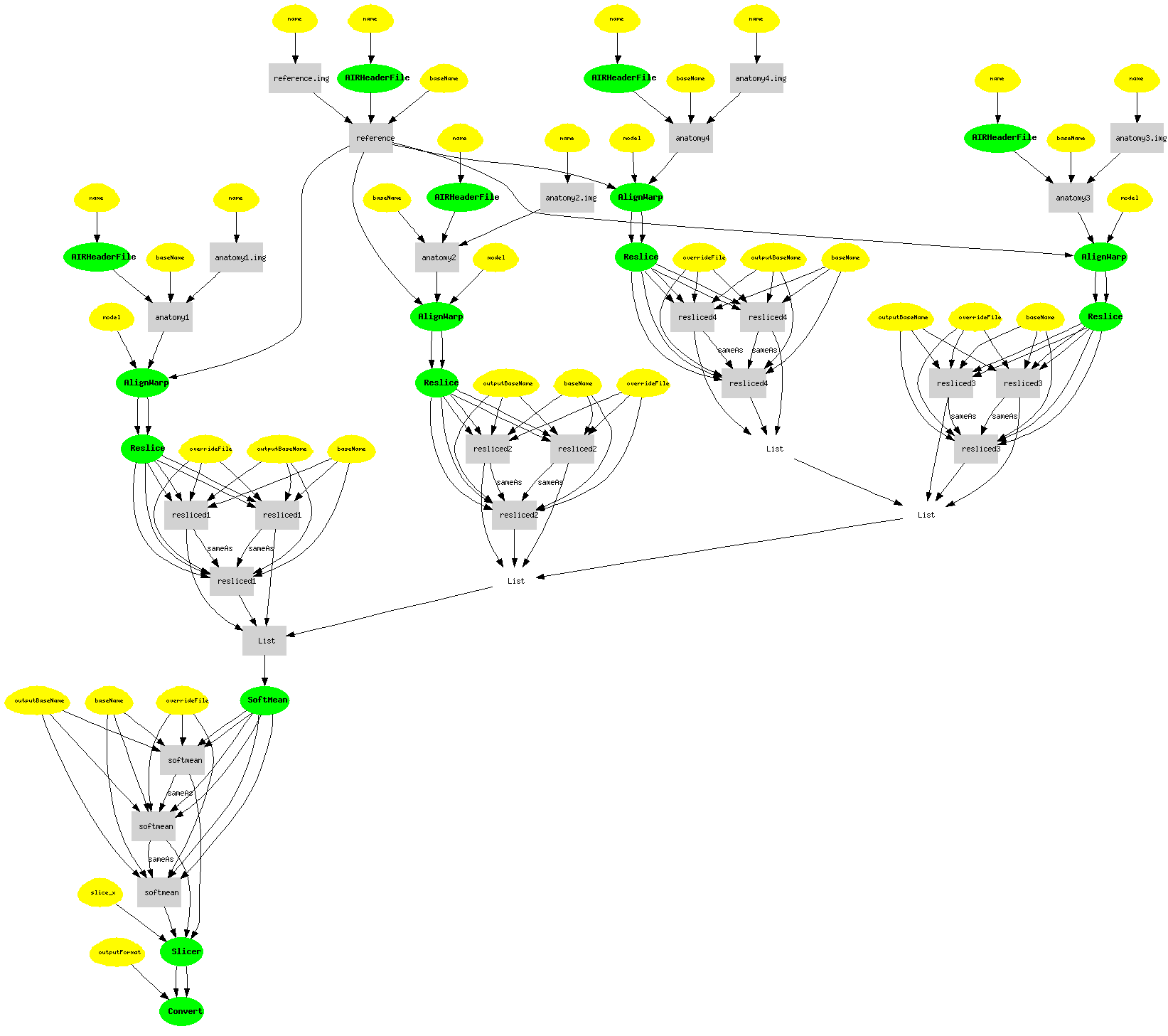 Mindswap
Query1:
Mindswap
Query1:
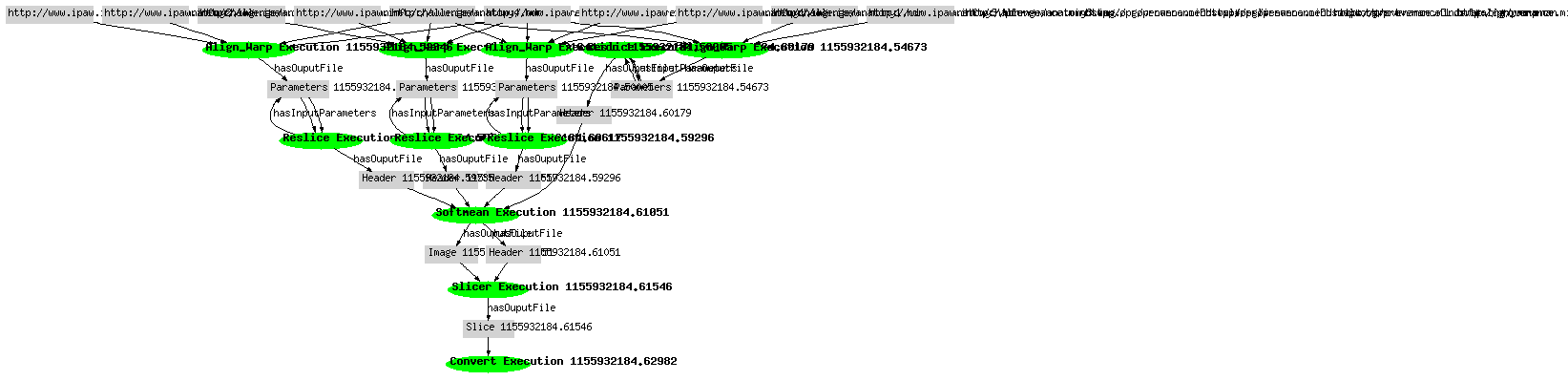
Translation Details
The translation of VisTrails was performed using primarily XSLT, it was mapped from XML to extract RDF which would adhere to our schema. We only extracted a subset of the data represented. There was additional information, representing the workflow representation that we did not import. After translating to rdf we also needed to infer object types and certain properties (such as title) to represent the workflow correctly within our result image. This information was inferred based on rdf types and other values extracted from the xml. Several relationship properties, such as has Input/Output were also inferred based on object type. The translation of Mindswap was performed primarily using OWL. The mapping was described between one schema and another and the queries performed based on properties inferred by that mapping. We noticed that information seemed to be lacking about the initial files of the workflow (the anatomy headers and images), for this reason they could only be represented as uris in the query result. In both cases when combining across data sources, we needed to assert which nodes in the graph corresponded to nodes in a different graph (for example, the reslice headers in our data were associated with the reslice headers in the mindswap data.)Benchmarks
Describe your proposed benchmark queries, how the comparable quantities are determined, and the results of applying the benchmark to your own systemFurther Comments
Provide here further comments.Conclusions
Provide here your conclusions on the challenge, and issues that you like to see discussed at a face to face meeting. -- KarenSchuchardt - 22 Jun 2007to top
| I | Attachment  | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| | stage1-final.xml | manage | 57.8 K | 26 Jan 2007 - 18:54 | KarenSchuchardt | Main workflow - Stage 1 Results |
| | stage2-final.xml | manage | 10.1 K | 26 Jan 2007 - 18:56 | KarenSchuchardt | Main workflow - Stage 2 Results |
| | stage3-final.xml | manage | 18.7 K | 26 Jan 2007 - 18:56 | KarenSchuchardt | Main workflow - Stage 3 Results |
| | q7-stage1-final.xml | manage | 57.8 K | 26 Jan 2007 - 18:57 | KarenSchuchardt | Query 7 Workflow - Stage 1 Results |
| | q7-stage2-final.xml | manage | 10.5 K | 26 Jan 2007 - 18:57 | KarenSchuchardt | Query 7 Workflow - Stage 2 Results |
| | q7-stage3-final.xml | manage | 22.4 K | 26 Jan 2007 - 18:58 | KarenSchuchardt | Query 7 Workflow - Stage 3 Results |
| | provmodel.tif | manage | 309.1 K | 12 Feb 2007 - 21:37 | KarenSchuchardt | prov data model graphically |
| | stage1-pnl.owl | manage | 70.3 K | 23 Jun 2007 - 00:48 | KarenSchuchardt | New stage 1 file |
| | stage2-pnl.owl | manage | 27.7 K | 23 Jun 2007 - 00:49 | KarenSchuchardt | New stage 2 file |
| | stage3-pnl.owl | manage | 86.6 K | 23 Jun 2007 - 00:49 | KarenSchuchardt | New stage 3 file |
| | sdg-provenanceDL.owl | manage | 13.1 K | 23 Jun 2007 - 00:50 | KarenSchuchardt | New SDG data model |
| | q1vt.gif | manage | 41.1 K | 23 Jun 2007 - 00:58 | KarenSchuchardt | Query 1 result image - VisTrails |
| | q1ms.gif | manage | 13.6 K | 23 Jun 2007 - 00:59 | KarenSchuchardt | Query 1 result image - Mindswap |
{kind=link}
{kind=link}
Edit | Attach image or document | Printable version | Raw text | More topic actions
Revisions: | r1.6 | > | r1.5 | > | r1.4 | Total page history | Backlinks
Revisions: | r1.6 | > | r1.5 | > | r1.4 | Total page history | Backlinks