Challenge
Start of topic | Skip to actions
University of Chicago - Provenance Challenge 1 - Summary
Participating Team
- Short team name: UChicago
- Participant/contributors: Ben Clifford, Ian Foster, Jens Voeckler (ISI), Mike Wilde, Yong Zhao
- Project URL: http://www.griphy.org/vds
- Project Overview: The Virtual Data System (VDS) describes workflows in a location-independent manner for execution in a variety of centralized and distributed environments.
- Provenance-specific Overview: VDS tracks the provenance of all data transformations it executes, and integrates this provenance closely with the workflows definitions.
- Relevant Publications: see project URL, above.
Workflow Representation
The challenge workflow is encoded in the Virtual Data Language (VDL). VDL is described in the VDS USers Guide. The full workflow is at: genatlas.vdl. An excerpt is included here:
TR air::align_warp( in refimg, in refhdr, in subimg, in subhdr, model, quick, out warp )
{
argument = ${refimg};
argument = ${subimg};
argument = ${warp};
argument = "-m " ${model};
argument = ${quick};
}
TR air::reslice( in warp, in subimg, in subhdr, out slicedimg, out slicedhdr )
{
argument = ${warp};
argument = ${slicedimg};
}
...
DV wilde.pc1.wf01::align_warp.1->air::align_warp(
refhdr = @{in:"Data/Raw/reference.hdr"},
refimg = @{in:"Data/Raw/reference.img"},
subhdr = @{in:"Data/Raw/anatomy1.hdr"},
subimg = @{in:"Data/Raw/anatomy1.img"},
warp = @{out:"Data/Derived/warp1.warp"},
model = "12",
quick = "-q"
);
DV wilde.pc1.wf01::reslice.2->air::reslice(
warp = @{in:"Data/Derived/warp1.warp"},
subhdr = @{in:"Data/Raw/anatomy1.hdr"},
subimg = @{in:"Data/Raw/anatomy1.img"},
slicedhdr = @{out:"Data/Derived/resliced1.hdr"},
slicedimg = @{out:"Data/Derived/resliced1.img"}
);
A few notes on VDL:
- there are two kinds of declarations in a VDL workflow: function definitions (TR for transformation) and function calls (DV for derivation). TRs in this version of the VDS represent executable applications with POSIX invocation attributes and execution conventions (such as environment variables and return codes).
- VDL definitions are stored in a database (relational or XML) where they can be joined with records of runtime provenance.
- VDL definitions TRs and DVs are fully named by triples of (namespace, name, version) eg: air::softmean:5.3. The namespace and version is optional, but all definitions must be unique within a virtual data catalog database.
- The schema of the virtual data catalog is represented (approximately) by the following high-level ER diagram:
- VDL workflows are location independent all applications and data files are logical and are translated to physical names as a part of the VDL workflow planning process.
- VDL workflows can be executed on a local host, on a cluster, or on a Grid (a distributed set of clusters). For this exercise we executed the challenge workflow on a local host evitable.ci.uchicago.edu.
- The VDS is typically used through a command line interface with the following commands:
- vdlt2vdlx converts VDL workflows from textual to XML format
- insertvdc inserted VDL definitions (in XML form) into a VDC database
- gendax traverses the data flow edges in the workflow graph represented in a VDC database, and produces a graph whose edges represent explicit paths of control.
- the vdlc command combines the three commands above into a single command, in the style of cc.
- shplanner the planner which generates shell scripts for local execution.
- kickstart this is an application launcher used within workflow both local and distributed at runtime, to gather run-time provenance from the applications execution in a uniform manner. Kickstart describes the applications execution (arguments, environment, duration, exitcode, system resources used, as well as the attributes of the application executable and all input and output data files. This description is in the form of an XML document called an invocation document, or sometimes simply a kickstart record.
- exitcode this helper application takes kickstart records and copies their content into the VDC, into a set of tables within the VDC schema called the provenance tracking catalog, or PTC. Exitcode also permits workflow engines such as DAGman to be sure that it can react to the exitcode of the application.
- When executed on a local host, the workflow is translated by a planner into a simple sequential shell script (actually, a nested collection of shellscripts one script for each derivation that is to be run, and one master script that invokes the subshell scripts in sequence.
- we chose to represent it as explicit DVs this lets us control all intermediate filenames as well as each DV name. Alternatively we could have represented it as nested compound transformations, which would enable us to write the workflow with far fewer DVs.
- we used a workflow name of pc1.wf01 as the namespace for DVs. For the TRs we used three different namespaces to reflect the origins of the code: air::, fsl::, and unix::.
- we named each DV as the name of the TR plus a DV sequence number (1-15) within the workflow
Provenance Trace
Upload a representation of the information you captured when executing the workflow. Explain the structure (provide pointers to documents describing your schemas etc.) We generated a DAX using the VDLC command, which compiles the VDL, inserts a representation of it into the virtual data catalog database, and then traverses the graph of transformation calls ("derivations" - the nodes) and their datadependencies (the edges) in the VDL produce a workflow. [Directed acyclic graph in XML DAX document] [Compiled workflow graph] This document describes the explicit control flow graph. It contains three sections:- A list of all logical file names used in the workflow, and their usage direction (in,out,or intermediate - inout).
- A list of all the derivations 9"jobs") to perform in the workflow
- A list of all the workflow graph edges in the form of child-to-parent control flow dependencies.
Provenance Queries
Provence quriees in the VDS can take several forms: SQL queries on the virtual data catalog, XML-filtering queries (performed in this exercise using text tools such as awk, but which can conceptually (and more properly) be done using XPath and XQuery), and plain text-filtering queries. These three mechanisms are joined in ad-hoc but expedient manners as illustrated below. In general, throughout our queries, we use gendax to perform graph traversals on the VDL definitions in the virtual data catalog database, and then tex tools to traverse that graph in its XML file format, and join this information with SQL queries using shell scripts. Note that several queries are performed entirely in SQL.Query 1
Find the process that led to Atlas X Graphic / everything that caused Atlas X Graphic to be as it is. This should tell us the new brain images from which the averaged atlas was generated, the warping performed etc. We perform a gendax to create the workflow graph for just the atlas x graphic. (Note that the executed workflow comprises the workflow graph to derive all three Atlas graphic files).# Get provenance for just the Atlas-X file gendax -o genatlasx.dax -l pc1.wf01 -f Data/Derived/atlas-x.gif prdax < genatlasx.dax >genatlasx.pro drawwf.sh genatlasxprdax is an awk script that formats the DAX document into humanly readable report-like format, and augments the workflow graph from the DAX with the runtime invocation provenance information from the virtual data catalog. Note that the workflow has already been executed gendax (a Java app) performs a graph traversal of the virtual data catalog (RDBMS), to select the derivation definitions required to derive the requested file. Passing gendax the same workflow id as the wf we ran allows us to match the invocation records in the database with the steps of the requested subgraph. The result files for this query are: The DAX graph: genatlasx.dax The Provenance (process record) file: genatlasx.pro Graphical renderings of the process graph, at various levels of detail, in png and svg:
- genatlasx.p.viz.png:
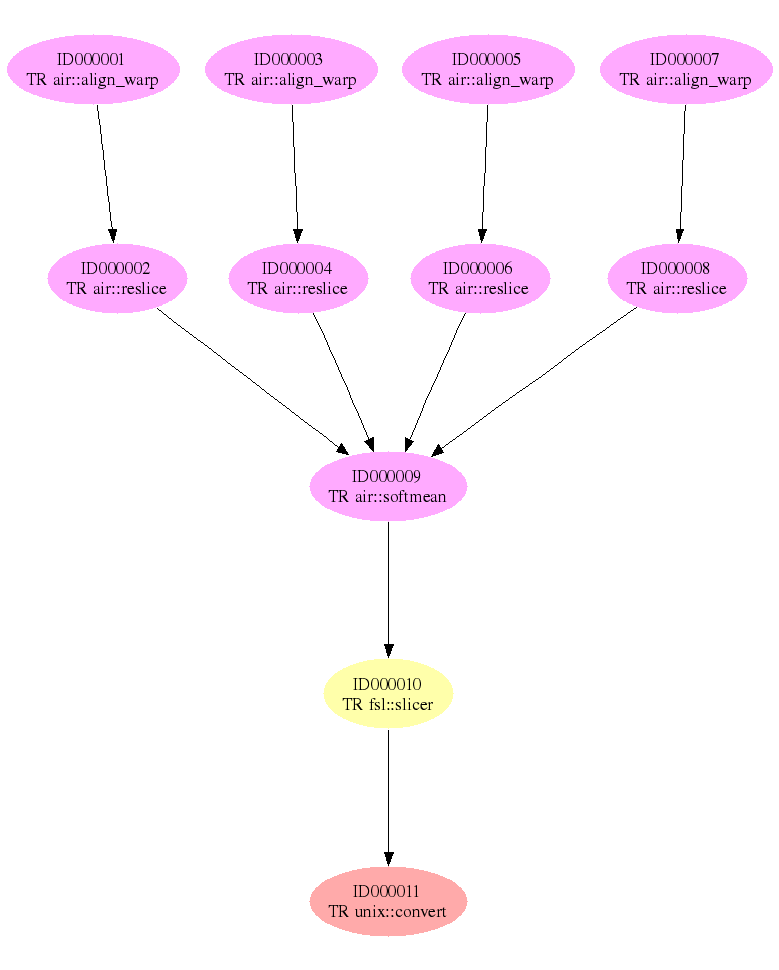
- SVG of high level graph
- SVG of detailed graph with file dependencies shown:
Query 2
Find the process that led to Atlas X Graphic, excluding everything prior to the averaging of images with softmean. This query asks us to filter a workflow graph. We take prior to to mean all graph predecessors of softmean. We do a graph traversal from the specified node (softmean) and go backwards through the workflow graph opposite to the direction of execution, from the sync to the source eliminating all predecessor nodes of the target node. The script exclude_prior performs this pruning on the XML workflow graph document (the genatlas.dax file), producing a new workflow document, the exuptosoftmean.dax We then run the prdax script on this graph to produce the provenance list.$ exclude_prio ID000009 <genatlas.dax >exuptosoftmean.dax $ prdaxThe provenance of the pruned workflow can be seen in these two files: Note that we specify the softmean job here with its Job ID (with no loss of generality). The exclude_prio script reads the dax file, constructs the graph in associative array objects (as a successor list) and uses the recursive function elim to remove graph elements that we wish to prune:
function elim(node,plist) {
delete jobtext[node];
if ( ! (node in parlist) ) return;
split(parlist[node], plist, " ")
for ( p in plist ) {
elim(plist[p]);
}
delete parlist[node];
}
j = jobtext["$exjob"];
elim("$exjob");
jobtext["$exjob"] = j;
The full source for exclude_prior is here: exclude_prior.
Query 3
Find the Stage 3, 4 and 5 details of the process that led to Atlas X Graphic. Query 3 is similar to query 2 but is based on stages of the workflow graph rather than on graph paths. Each derivation (invocation) in our workflow graphs is annotated with a level attribute, that signifies the level of the breadth-first graph traversal that was done to go from the requested data product of the workflow backwards to all the dependent data products and the derivations needed to produce them. These levels are the inverse of the stage numbers specied in the challenge problem. We apply a function maxlevel which obtains the maximum level of the workflow graph, and use this number to convert the request stage numbers to requested levels. Then, the work of this query is done in a manner very similar to that of query 2, using select_stage to prune out all levels of the graph outside of a specific range of stages: Select_stage calls maxlevel to convert stages to levels.$ select_stage 3 5 <genatlas.dax >genatlas.3-5.dax $ prdax <genatlas.3-5.dax >genatlas.3-5.pro
- genatlas.3-5.dax: pruned workflow graph (XML)
- genatlas.3-5.pro: resulting provenance
- select_stage: Source for the level pruner.
Query 4
Find all invocations of procedure align_warp using a twelfth order nonlinear 1365 parameter model (see model menu describing possible values of parameter "-m 12" of align_warp) that ran on a Monday. This is a straightforward SQL join of the invocation tables with the parameters of the DV (as given by the darg table). For days of the week, we use a SQL expression on the DV invocation date: SELECT EXTRACT(DOW FROM start) to pick a specific date. ((Sunday=0. Note that we queried for Tuesday (2) rather than Monday (1) to match our example run) but show a similar technique to query on a range of seconds of minute to test the approach. The query is:
-- invocations from Tuesday
SELECT iv.* from ptc_invocation iv, anno_definition def
WHERE def.id IN (
SELECT dvid
FROM darg da
WHERE dvid IN (
SELECT id FROM anno_definition WHERE xml like '<derivation%uses="align_warp"%'
)
AND da.name = 'model' AND da.value = 12
)
AND def.name = iv.dv_name
AND EXTRACT(DOW from iv.start) = 2;
-- invocations occuring < 20 seconds into the minute
SELECT iv.* from ptc_invocation iv, anno_definition def
WHERE def.id IN (
SELECT dvid
FROM darg da
WHERE dvid IN (
SELECT id FROM anno_definition WHERE xml like '<derivation%uses="align_warp"%'
)
AND da.name = 'model' AND da.value = 12
)
AND def.name = iv.dv_name
AND EXTRACT(SECONDS from iv.start) < 20;
The output in this simple test was a crued dump of all the fields of the invocation record as stored in the VDC database. While hard to read, it shows the richnes of the fields captured in the provenance record: uid, gid, pid, cwd, system architecture, and a pointer to the getruasge() record info:
-bash-3.00$ cat find_invo.out id | creator | creationtime | wf_label | wf_time | version | start | duration | tr_namespace | tr_name | tr_version | dv_namespace | dv_name | dv_version | resource | host | pid | uid | gid | cwd | arch | total ----+---------+----------------------------+----------+----------------------------+---------+----------------------------+----------+--------------+------------+------------+----------------+--------------+------------+----------+-----------------+-------+------+------+-------------------------+------+------- 80 | wilde | 2006-09-12 09:46:34.068-05 | pc1.wf01 | 2006-10-10 19:00:01.219-05 | 1.7 | 2006-09-12 09:44:16.749-05 | 3.759 | air | align_warp | | wilde.pc1.wf01 | align_warp.3 | | local | 128.135.125.191 | 19843 | 1031 | 1000 | /autonfs/home/wilde/pc1 | 3 | 160 79 | wilde | 2006-09-12 09:46:33.946-05 | pc1.wf01 | 2006-10-10 19:00:01.219-05 | 1.7 | 2006-09-12 09:44:11.526-05 | 4.008 | air | align_warp | | wilde.pc1.wf01 | align_warp.1 | | local | 128.135.125.191 | 19817 | 1031 | 1000 | /autonfs/home/wilde/pc1 | 3 | 158 81 | wilde | 2006-09-12 09:46:34.141-05 | pc1.wf01 | 2006-10-10 19:00:01.219-05 | 1.7 | 2006-09-12 09:44:26.981-05 | 3.75 | air | align_warp | | wilde.pc1.wf01 | align_warp.5 | | local | 128.135.125.191 | 19893 | 1031 | 1000 | /autonfs/home/wilde/pc1 | 3 | 162 82 | wilde | 2006-09-12 09:46:34.222-05 | pc1.wf01 | 2006-10-10 19:00:01.219-05 | 1.7 | 2006-09-12 09:44:21.771-05 | 4.008 | air | align_warp | | wilde.pc1.wf01 | align_warp.7 | | local | 128.135.125.191 | 19867 | 1031 | 1000 | /autonfs/home/wilde/pc1 | 3 | 164 (4 rows) id | creator | creationtime | wf_label | wf_time | version | start | duration | tr_namespace | tr_name | tr_version | dv_namespace | dv_name | dv_version | resource | host | pid | uid | gid | cwd | arch | total ----+---------+----------------------------+----------+----------------------------+---------+----------------------------+----------+--------------+------------+------------+----------------+--------------+------------+----------+-----------------+-------+------+------+-------------------------+------+------- 80 | wilde | 2006-09-12 09:46:34.068-05 | pc1.wf01 | 2006-10-10 19:00:01.219-05 | 1.7 | 2006-09-12 09:44:16.749-05 | 3.759 | air | align_warp | | wilde.pc1.wf01 | align_warp.3 | | local | 128.135.125.191 | 19843 | 1031 | 1000 | /autonfs/home/wilde/pc1 | 3 | 160 79 | wilde | 2006-09-12 09:46:33.946-05 | pc1.wf01 | 2006-10-10 19:00:01.219-05 | 1.7 | 2006-09-12 09:44:11.526-05 | 4.008 | air | align_warp | | wilde.pc1.wf01 | align_warp.1 | | local | 128.135.125.191 | 19817 | 1031 | 1000 | /autonfs/home/wilde/pc1 | 3 | 158 (2 rows)
Query 5
Find all Atlas Graphic images outputted from workflows where at least one of the input Anatomy Headers had an entry global maximum=4095. The contents of a header file can be extracted as text using the scanheader AIR utility. This query treats the entire workflow as a black box, and assumes, for example, that many workflows have been run, and that we are looking for the output products of workflows whose inputs meet a metadata criterion. We run a simple script (which could itself be captured as a workflow) to turn the headers into metadata and reattach this metadata to the headers. The query script - which integrates SQL on the VDC with awk to query the DAX XML workflow - is:
targetfiles=`mktemp /tmp/query5.XXXXXX`
derivedfiles=`mktemp /tmp/query5.XXXXXX`
targetpattern=`mktemp /tmp/query5.XXXXXX`
psql -t -d mwvdc1 -U wilde -f - <<EOF >$targetfiles
SELECT lfn.name FROM anno_lfn lfn, anno_int ai
WHERE
lfn.name like '%/anatomy%.hdr'
and lfn.id = ai.id
and ai.value = 4095;
EOF
psql -t -d mwvdc1 -U wilde -f - <<EOF >$derivedfiles
SELECT of.name FROM anno_lfn_o of
WHERE
of.name like '%/atlas%.gif' OR
of.name like '%/atlas%.pgm'
EOF
sed -e 's/^ //' \
-e '/^$/d' \
-e 's/^/ <filename file="/' \
-e 's/$/" link="input"\/>/' <$targetfiles >$targetpattern
for d in `cat $derivedfiles` ; do
gendax -f $d | grep -q -F "`cat $targetpattern`" && echo $d
done
rm $targetfiles $derivedfiles $derivedpattern
Query 6
Find all output averaged images of softmean (average) procedures, where the warped images taken as input were align_warped using a twelfth order nonlinear 1365 parameter model, i.e. "where softmean was preceded in the workflow, directly or indirectly, by an align_warp procedure with argument -m 12. We use a similar approach to that of query 5:
# Find align_warp calls with argument model=12
psql -t -d mwvdc1 -U wilde -A -F ' ' -f - <<EOF >$alignwarpdvs
SELECT def.namespace, def.name, def.version from darg da, anno_definition def
WHERE da.name = 'model' AND da.value = 12
AND da.dvid = def.id
EOF
# Find all softmean derivations
psql -t -d mwvdc1 -U wilde -A -F ' ' -f - <<EOF >$softmeandvs
SELECT def.namespace, def.name, def.version from anno_definition def
WHERE def.xml LIKE '%uses="softmean"%';
EOF
# Form DV pattern to search workflow graphs
cat <<EOF >$awkp
{ line="";
if( \$1 != "") {line = line "dv-namespace=\"" \$1 "\""; }
if( \$2 != "") {line = line " dv-name=\"" \$2 "\""; }
if( \$3 != "") {line = line " dv-version=\"" \$3 "\""; }
print line;
}
EOF
awk -f $awkp <$alignwarpdvs >$dvpattern
# Find workflows of softmean derivations that contain the desired preceding align_warp DVs
# and select the output images of these workflows
while read ns name ver; do
gendax -o $dax -n "$ns" -i "$name" -v "$ver"
grep -q -F "`cat $dvpattern`" $dax && grep 'filename.*img.*output' $dax
done <$softmeandvs
Query 8
A user has annotated some anatomy images with a key-value pair center=UChicago. Find the outputs of align_warp where the inputs are annotated with center=UChicago. This query is done entirely in SQL on the VDC:
Find lfns with annotation center=uc
Find alignwarp Dvs with those lfns as inputs
Find outputs of these DVs
(need to add more data to show the selectivity of this query)
SELECT outf.name
FROM anno_lfn_i inf, anno_lfn_o outf, anno_definition dv
WHERE inf.name in (
SELECT lfn.name FROM anno_lfn lfn, anno_text txt
WHERE mkey='center'
AND txt.id = lfn.id
AND txt.value = 'UChicago'
)
AND inf.did = dv.id
AND dv.xml like '%uses="align_warp"%'
AND dv.id = outf.did;
name
-------------------------
Data/Derived/warp2.warp
Data/Derived/warp4.warp
(2 rows)
Query 9
A user has annotated some atlas graphics with key-value pair where the key is studyModality. Find all the graphical atlas sets that have metadata annotation studyModality with values speech, visual or audio, and return all other annotations to these files. For this query we create 10 new logical file records, and annotate them with test data. The Query, like #8, is entirely in SQL on the VDC:
SELECT lfn.name, lfn.mkey, txt.value
FROM anno_lfn lfn, anno_text txt
WHERE lfn.id = txt.id
AND lfn.name in (
SELECT lfn1.name FROM anno_lfn lfn1, anno_lfn lfn2, anno_text txt1, anno_text txt2
WHERE lfn1.mkey='datatype'
AND txt1.id = lfn1.id
AND txt1.value = 'graphics'
AND lfn2.mkey='studyModality'
AND lfn2.id = txt2.id
AND txt2.value in ('speech', 'audio', 'visual')
AND lfn1.name = lfn2.name
) ORDER BY lfn.name;
SELECT lfn.name, lfn.mkey, flt.value
FROM anno_lfn lfn, anno_float flt
WHERE lfn.id = flt.id
AND lfn.name in (
SELECT lfn1.name FROM anno_lfn lfn1, anno_lfn lfn2, anno_text txt1, anno_text txt2
WHERE lfn1.mkey='datatype'
AND txt1.id = lfn1.id
AND txt1.value = 'graphics'
AND lfn2.mkey='studyModality'
AND lfn2.id = txt2.id
AND txt2.value in ('speech', 'audio', 'visual')
AND lfn1.name = lfn2.name
) ORDER BY lfn.name;
$ query9
name | mkey | value
+----------------------+---------------+----------
Data/Raw/anatomy10.img | studyAgency | NSF
Data/Raw/anatomy10.img | studyPI | Moreau
Data/Raw/anatomy10.img | studyModality | speech
Data/Raw/anatomy10.img | datatype | graphics
Data/Raw/anatomy10.img | center | UChicago
Data/Raw/anatomy11.img | studyState | complete
Data/Raw/anatomy11.img | studyAgency | NSF
Data/Raw/anatomy11.img | studyPI | Moreau
Data/Raw/anatomy11.img | studyModality | audio
Data/Raw/anatomy11.img | datatype | graphics
Data/Raw/anatomy11.img | center | Oxford
Data/Raw/anatomy12.img | studyAgency | NSF
Data/Raw/anatomy12.img | studyPI | Moreau
Data/Raw/anatomy12.img | studyModality | visual
Data/Raw/anatomy12.img | datatype | graphics
Data/Raw/anatomy12.img | center | UChicago
Data/Raw/anatomy14.img | studyState | complete
Data/Raw/anatomy14.img | studyAgency | NSF
Data/Raw/anatomy14.img | studyPI | Groth
Data/Raw/anatomy14.img | studyModality | speech
Data/Raw/anatomy14.img | datatype | graphics
Data/Raw/anatomy14.img | center | UChicago
Data/Raw/anatomy15.img | studyAgency | NSF
Data/Raw/anatomy15.img | studyPI | Moreau
Data/Raw/anatomy15.img | studyModality | speech
Data/Raw/anatomy15.img | datatype | graphics
Data/Raw/anatomy15.img | center | London
Data/Raw/anatomy16.img | studyAgency | NSF
Data/Raw/anatomy16.img | studyPI | Moreau
Data/Raw/anatomy16.img | studyModality | speech
Data/Raw/anatomy16.img | datatype | graphics
Data/Raw/anatomy16.img | center | Kyoto
Data/Raw/anatomy18.img | studyAgency | NSF
Data/Raw/anatomy18.img | studyPI | Moreau
Data/Raw/anatomy18.img | studyModality | speech
Data/Raw/anatomy18.img | datatype | graphics
Data/Raw/anatomy18.img | center | UChicago
(37 rows)
name | mkey | value
+-----------------------+-----------+------------------
Data/Raw/anatomy15.img | studyCost | 12500.9501953125
(1 row)
Suggested Workflow Variants
Suggest variants of the workflow that can exhibit capabilities that your system support.Suggested Queries
Suggest significant queries that your system can support and are not in the proposed list of queries, and how you have implemented/would implement them. These queries may be with regards to a variant of the workflow suggested above.Categorisation of queries
According to your provenance approach, you may be able to provide a categorisation of queries. Can you elaborate on the categorisation and its rationale.Live systems
If your system can be accessed live (through portal, web page, web service, or other), provide relevant information here.Further Comments
Provide here further comments.Conclusions
Provide here your conclusions on the challenge, and issues that you like to see discussed at a face to face meeting. -- MichaelWilde - 12 Sep 2006to top
| I | Attachment  | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| | initrc.sh | manage | 1.7 K | 13 Sep 2006 - 10:38 | MichaelWilde |
Edit | Attach image or document | Printable version | Raw text | More topic actions
Revisions: | r1.5 | > | r1.4 | > | r1.3 | Total page history | Backlinks
Revisions: | r1.5 | > | r1.4 | > | r1.3 | Total page history | Backlinks