Challenge
Start of topic | Skip to actions
Second Provenance Challenge: VisTrails
Participating Team
- Short team name: VisTrails
- Participant names: Erik Anderson, Steven Callahan, Tommy Ellkvist, Juliana Freire, David Koop, Emanuele Santos, Carlos Scheidegger, Claudio Silva, Nathan Smith and Huy Vo
- Project URL: http://www.vistrails.org/
- First challenge results: VisTrails
- Presentation
Differences from First Challenge
We have changed the structure of our provenance representation to generalize and better structure our data, but the data stored is roughly equivalent to our previous representation. The schemas and data are provided below. Recall that we store workflow evolution in a vistrail which is a tree of actions where each node represents a (possibly partial) workflow. To allow easier integration with other systems, we have also materialized the individual workflow specifications for the three parts. We split our original workflow into three individual workflows to better reflect the independence of the parts. In addition, because the AIR tools depend on a (.hdr, .img) pair of files, the workflows are slightly restructed so that module inputs and outputs are also paired using a FileSet module.Provenance Data for Workflow Parts
The provenance data is split into three layers (workflow evolution, workflows, and execution). The schemas for these layers are available:- vistrail.xsd - workflow evolution actions
- workflow.xsd - workflow specification
- log.xsd - workflow execution information
- pc_vt.xml stores the workflow evolution (you can materialize workflows from this data)
- pc_part1.xml is the materialized workflow for part 1
- pc_part2.xml is the materialized workflow for part 2
- pc_part3a.xml is the materialized workflow for part 3 (first version)
- pc_part3b.xml is the materialized workflow for part 3 (second version)
- pc_log.xml is the execution information
Model Integration Results
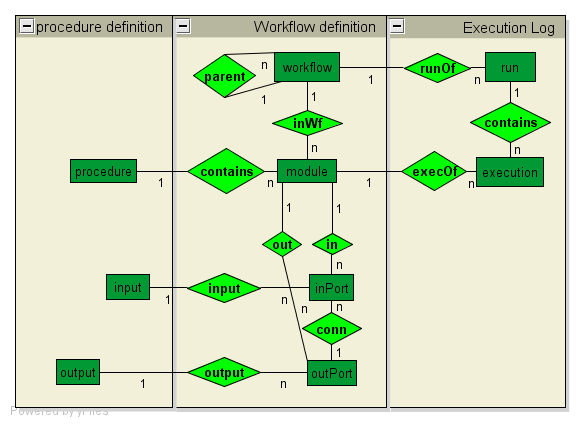
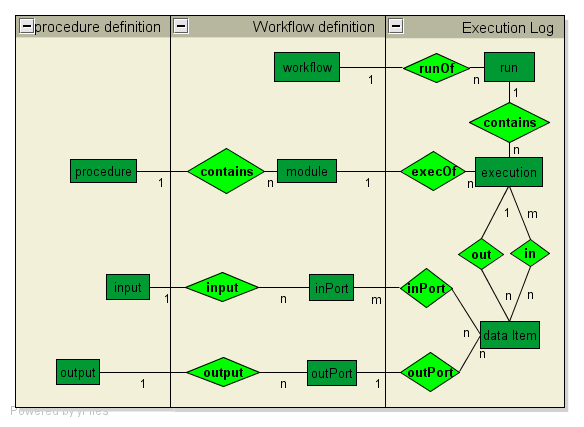
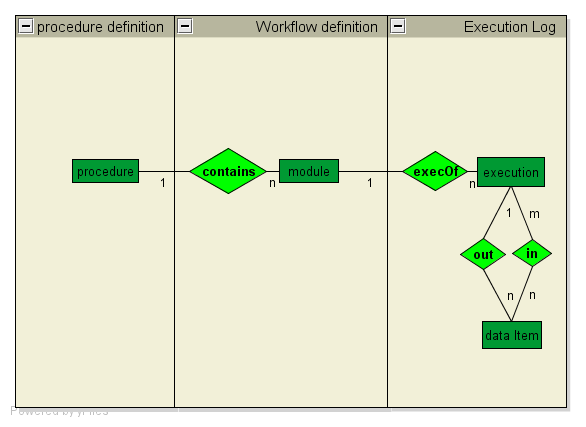
We have successfully performed most queries using data from VisTrails, MyGrid, and Southampton. We have included our own system because our new query API is general and not native to VisTrails.Model comparison
The VisTrails and MyGrid models were easy to use because of their simple data format, The generalized model of Southampton presented a greater challenge because of the many levels of nesting and abstractions. VisTrails required both the execution log and the workflow definition for the provenance queries whereas MyGrid and Southampton only needed the execution log. Finally, VisTrails supports a third level of provenance--the workflow evolution layer, and while we have not used it for this API, it has many benefits when asking queries about differences between workflows.| VisTrails |
|---|
 |
| MyGrid |
 |
| Southampton |
 |
Concepts
The concept of data item varies between systems. It can be represented as the data exchanged between modules, the inputs or outputs of a workflow or a file reference passed between modules. The concept of parameters, which are used in VisTrails to modify modules, does not exist in other models. MyGrid uses something similar to edit the parameters of modules (like setting file name to save to). This concept is not clearly defined. Southampton have the concept of assertion where every module/service records its own view of the process. This concept does not exist in the other systems and is not used in our provenance queries. But it might be important for validating results. Other concepts like modules/connections/executions are the same although most of them have different names.Method
Our method consists of using wrappers to translates the queries between a common data model and the source data. We first defined a high-level general model that captures the basic concepts of workflows and its executions. The model contains basic concepts making it possible to express queries over the different models. Second, we defined API functions for the wrappers that use this model. Finally, we implemented the wrappers and constructed the queries. This challenge sought to address how provenance from different systems can be connected. However, there was no requirement for data products to be consistently idenitifed. Thus, in order to connect provenance across different systems, we had to manually identify the mapping between output data from one workflow and input data for the next. This naming is an important consideration when coordinating workflows across different systems. One solution is to use more general identifiers like LSID's or some other standard identifier.Translation Details
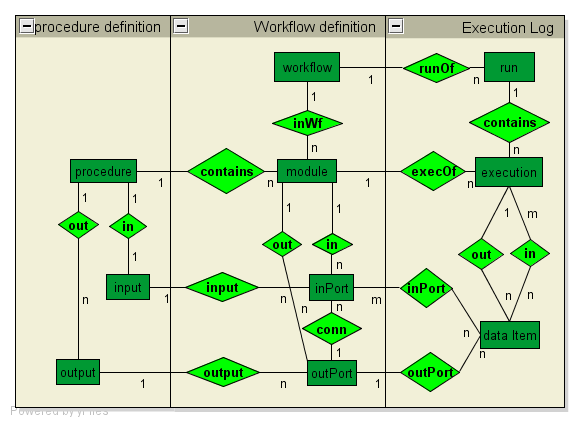
Scientific Workflow Provenance Data Model (SWPDM)
The SWPDM (shown above) is a general provenance model that aims to capture entities and relationships that are relevant to both the definition and execution of workflows. The goal is to define a general model that is able to represent provenance information obtained by different workflow systems.The API
Our model is instantiated as a query API that operates on the concepts in the model. Vertices are modeled as objects and edges as operations on these objects. There also exists more complex operations that can traverse more than one edge which are used to model common provenance query operations.Implementation
This API is implemented as wrappers on top of the different data models. These wrapper functions translates the queries into a native query on the source. Currently VisTrails and Southampton uses XML with XPath as the access method. In this case the queries are translated into XPath expressions. MyGrid uses RDF/XML on a SPARQL server and the queries are translated into SPARQL expressions. Using a combination of data sources (MyGrid->Southampton->Vistrails) we can now query the data using the API:
r2 = pqf.getAllAnnotated(pModuleInstance,[('outputName', 'eq', 'atlas-x.gif')])
prov = r2[0].getExecutionFromInstance()[0].upstream()
We then get the result:
vt3:4 --> vt3:7 vt3:1 --> vt3:4 vt3:0 --> vt3:1 pas2:http://relation.org/softmean --> vt3:0 myg1:urn:www.mygrid.org.uk/process#reslice1 --> pas2:http://relation.org/softmean myg1:urn:www.mygrid.org.uk/process#reslice2 --> pas2:http://relation.org/softmean myg1:urn:www.mygrid.org.uk/process#reslice3 --> pas2:http://relation.org/softmean myg1:urn:www.mygrid.org.uk/process#reslice4 --> pas2:http://relation.org/softmean myg1:urn:www.mygrid.org.uk/process#align_warp1 --> myg1:urn:www.mygrid.org.uk/process#reslice1 myg1:urn:www.mygrid.org.uk/process#align_warp2 --> myg1:urn:www.mygrid.org.uk/process#reslice2 myg1:urn:www.mygrid.org.uk/process#align_warp3 --> myg1:urn:www.mygrid.org.uk/process#reslice3 myg1:urn:www.mygrid.org.uk/process#align_warp4 --> myg1:urn:www.mygrid.org.uk/process#reslice4Which is the execution provenance trace of the file atlas-x.gif.
Benchmarks
The benchmark is done using Query 1 (Upstream of AtlasXGraphic). It is a good general upstream query that returns the module executions in the upstream. The data files are too small for a good benchmark but we have timed the queries using the different systems.MyGrid
opn = 'urn:www.mygrid.org.uk/process#convert1_out_AtlasXGraphic' rl = pqf.getNode(pOutputPort, opn, store3.ns).getDataFromOutPort()[0].getExecutionFromOutData()[0].upstream()1 sec
VisTrails
ar = [('outputName', 'eq', 'atlas-x.gif')]
r1 = pqf.getAllAnnotated(pModule,ar)[0].upstream()
0.1 sec
Southampton
odn = 'http://www.ipaw.info/challenge/atlas-x.gif' rl = pqf.getNode(pDataItem, odn, store3.ns).getExecutionFromOutData().upstream()1 sec
Benchmark results
Although these times are very short, there seem to be two main factors influencing the result: The query engine used and the size of the data. VisTrails is fastest using an XPath processor and a small amount of data. The MyGrid data file is small but it uses a SPARQL server which is slower than using XPath. Southampton uses XPath but has large data files. These results includes initialization of the wrapper and some extra pre-processing for Southampton to calculate the data links. But they have at most biased the result by a factor of 2.Further Comments
Provide here further comments.Conclusions
In the general case, tracking provenance through different systems is a data integration problem. But by defining a common model (SWPDM) on a restricted domain (Scientific Workflow) the difficulty is reduced to efficiency and entity resolution problems. We believe that it should be possible for the Scientific workflow community to support a model similar to the SWPDM to enable provenance to be tracked through their systems. We have showed that an API for querying this model can be built and its compatibility with three of the current systems. Problems for discussion: How to connect these systems? There is a need for the data to support referencing other models. E.g. If a data item is stored externally and tracked through another provenance store. Common identifiers like LSID:s might be part of the solution. External data items should also be given a namespace to indicate where they came from. Is there a way to come up with common concepts for data items, they are used in many layers and have different meanings. How can a user easily express these kind of queries? Query complexity - Relational Algebra cannot express these kind of provenance queries because of the use of transitive closure. -- TommyEllkvist? - 21 Jun 2007to top
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach image or document | Printable version | Raw text | More topic actions
Revisions: | r1.9 | > | r1.8 | > | r1.7 | Total page history | Backlinks
Revisions: | r1.9 | > | r1.8 | > | r1.7 | Total page history | Backlinks