Rs
The Eight Rs of Research Objects
David De Roure, June 2009
Web 2's principle of "Data is the Next Intel Iside" reminds us that the value proposition of many Web 2 sites is their excellent support for one type of content - photos on flickr, slides on slideshare. But scientists don't work with just one type - they work with collections of "stuff". In myExperiment we began with workflows as our value proposition - because we spotted the need, and because we believe in sharing methods to share scientific know-how, and because we believe in starting with the specific. Then we introduced packs: A pack lets the researcher collect a number of different pieces together and teat them as one sharable entity. In the UI this is based on the metaphor of the shopping cart or wish list.
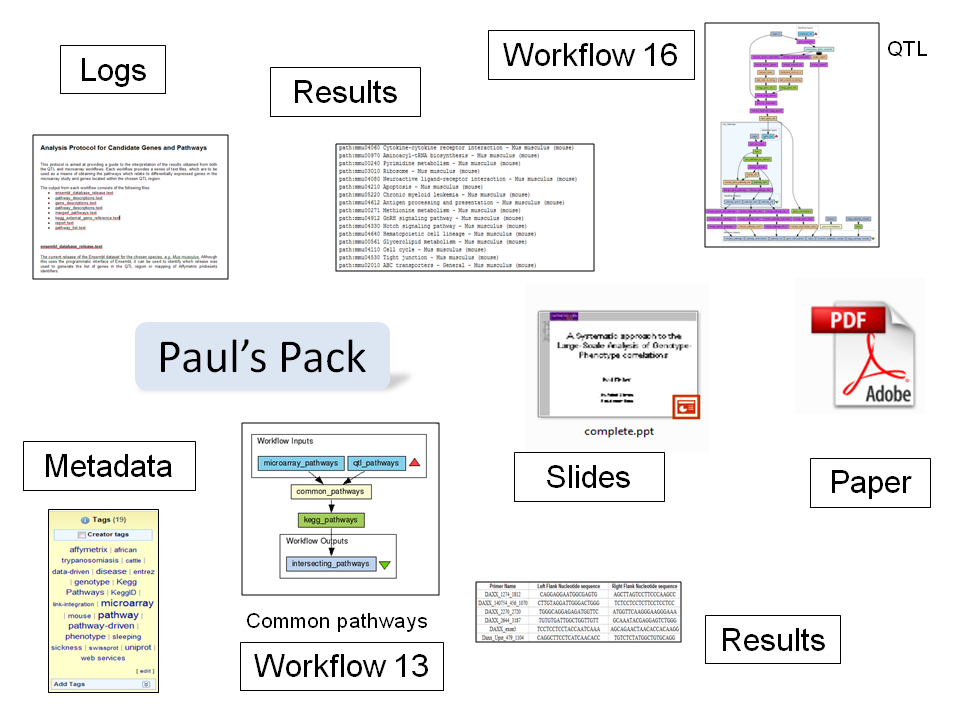
A pack is an example of what we now call a Research Object, and we are beginning to elaborate on what we mean by that. An excellent example is Paul Fisher's pack for his tryps work, and then the pack of all the parts for our CCPE paper which uses Paul's pack as an example. Paul annotated the pack with arrows and labels - this is what we need in a Research Object, and that's why we're now engaged with Tim Clark's SWAN-SIOC work, and also with Luc Moreau and his Open Provenance Model (OPM), and also with Carol Lagoze's OAI Object Reuse and Exchange representation which we use when we export packs in RDF using David Newman's modularised myExperiment ontology. David Shotton in Oxford has also provided an excellent example of semantic publishing. We are also gaining, from our users, a sense of what makes a good Research Object - for example, a workflow complete with example input and output data provides a means of checking the workflow still does what it used to (thanks to Werner Müller for highlighting this approach). One day perhaps we'll have a barometer telling you how good your Research Object is, like password security strength or filling out user profiles.
{kind=link}
{kind=link}
To define a Research Object we need to understand its characteristics. We've occasionally used the word "reproducible" in presentations, and there is a literature on "reproducible research". When I was working up my talk for the panel at ESWC 2009 I took the provocative position that a paper is just an "archaic human-readable form of a Research Object", and that in the future we won't say "can I have a copy of your paper please" but rather "could you share that research object with me please?" To present this I created a slide of words beginning with R (in fact, "Re.*") which characterise a Research Object, and this has evolved through several talks. These are the Rs as they are now, on a Wiki page so they can continue to evolve in public. They are the 8 things which Research Objects enable research to be.
Contents
- 1 Replayable – go back and see what happened
- 2 Repeatable – run the experiment again
- 3 Reproducible – run new experiment to reproduce the results
- 4 Reusable – use as part of new experiments
- 5 Repurposeable – reuse the pieces in new expt
- 6 Replicatable – run more of the same
- 7 Reliable – robust under automation
- 8 Reflective – self-described and self-contained
Replayable – go back and see what happened
Experiments are automated. They might happen in millseconds or months. Either way, the ability to replay the experiment, and to study parts of it, is essential for human understanding of what happened.
Repeatable – run the experiment again
There's enough in a Research Object for the researcher to be able to repeat the experiment, perhaps years later, in order to verify the results or validate the experimental environment.
Reproducible – run new experiment to reproduce the results
As every scientist knows, this is different to repeatable. To reproduce a result is for someone else to start with the same materials and methods and see if a prior result can be confirmed.
Reusable – use as part of new experiments
One experiment may call upon another - an experiment may be used in a context other that that in which it ewas originally conceived. By assembling methods in this way we can conduct research, and ask research questions, at a higher level.
Repurposeable – reuse the pieces in new expt
An experiment which is a black box is only reuaeable as a black box. By opening the lid we find parts, and cobinations of parts, available for reuse, and the way they are assembled is a clue to how they can be re-used.
Replicatable – run more of the same
The scale of data intensive science means lots of replication of processing - to deal with the deluge of data or indeed the deluge of methods. It should be possible to copy a research object and use it somewhere else.
Reliable – robust under automation
Automation brings systematic and unbiased processing, and also "unattended experiments" - human out the loop. In data-intensive science, Research Objects promote reliable experiments, but also they must be reliable for automated running.
Reflective – self-described and self-contained
A research object is self-contained and self-describing - it contains enough metadata to have all the above characteristics and for a e-Lab component or service to make sense of it. To the computer scientist this term means you can run a Research Object like a program but you can also look inside it like data - i.e. it supports reflection.