

A visual system that could predict the visibility and invisibility of objects undergoing occlusion and disocclusion would ipso facto constitute a representation of the depth relations between the occluded and occluding objects. We considered many mechanisms whereby a visual system could learn to generate such predictions.
The basic structure of our networks is one in which a stage of neurons receives a variety of inputs. Some neurons receive strong bottom-up excitatory connections from preprocessing stages; these connections transmit information about actual image data. Some neurons receive strong time-delayed lateral excitatory connections from other neurons within the same stage; these connections transmit priming excitation from neurons activated at one moment to the neurons predicted to be active at the next moment. All neurons receive lateral inhibitory connections from some other neurons; these serve to enforce competitive decision-making in the interpretation of visual input patterns.
Within this scheme, there might exist three classes of neurons at each spatial position in the network. Class I neurons receive both strong bottom-up excitatory and strong lateral excitatory connections (Figure 2a). These neurons respond preferentially to events where a visual object moves as predicted, without being occluded or disoccluded.
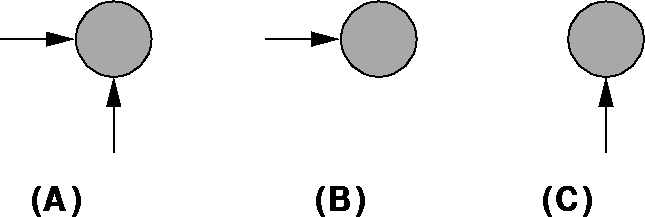
Figure 2:
Three classes of neurons for detecting occlusion events.
(a) Class I neurons receive both bottom-up and lateral afferents.
(b) Class II neurons receive primarily lateral afferents.
(c) Class III neurons receive primarily bottom-up afferents.
Class II neurons receive strong lateral excitatory but weak bottom-up excitatory connections (Figure 2b). These neurons respond preferentially to events where a moving visual object is predicted (lateral excitation) to appear farther along its trajectory but fails to appear at the predicted place (lack of bottom-up excitation). Such excitation patterns typically arise during occlusion events.
Class III neurons receive strong bottom-up excitatory but weak lateral excitatory connections (Figure 2c). These neurons respond preferentially to events where a visual object freshly appears (bottom-up excitation) without having been predicted (lack of lateral excitation). Such excitation patterns typically arise during disocclusion events.