SotonProvenance
Start of topic | Skip to actions
PrIMe: The Provenance Methodology
This page describes the Provenance Incorporating Methodology (PrIMe).Introduction
Provenance is already well understood in the study of fine art where it refers to the trusted, documented history of some art object. Given that documented history, the object attains an authority that allows scholars to understand and appreciate its importance and context relative to other works. Art objects that do not have a trusted, proven history may be treated with some scepticism by those that study and view them. This same concept of provenance may also be applied to data and information generated within computer applications. In general, computer applications produce data, and making an application provenance-aware allows its users to understand the provenance of their data, understood as the process that led to that data. To be able to determine the provenance of data, it must be possible to document an application's execution and to then perform queries over that documentation. Such documentation is called process documentation and is comprised of multiple, individual pieces of information, called p-assertions, which are recorded during execution and then stored and maintained in a repository of such information called a provenance store. One difficulty that remains, however, is to ensure that necessary and sufficient forms of process documentation are captured so that queries can return a satisfactory account of a given data item's provenance. It is the role of such software engineering tools as PrIMe to ensure this is achieved. PrIMe is a tool to be used by system developers who make modifications to applications by applying the steps of PrIMe after querying the application's users for the kinds of information they require from their application. By applying PrIMe, developers can make applications provenance-aware, which are then able to satisfy provenance use cases, where a use case is a description of a scenario in which a user interacts with a system by performing particular functions on that system, and a provenance use case is a use case requiring documentation of past processes in order to achieve the functions. The provenance architecture satisfies provenance use cases by making extra information available: documentation of past processes and extra information that can be derived from such documentation. PrIMe is a guided approach to makeing application information available to querying actors by modifying an application through applying a series of well-specified adaptations. When developing provenance-aware applications, PrIMe aims to fulfill the following criteria. Usability PrIMe is easy to apply. Traceability All design decisions made using PrIMe can be traced back to the requirements that informed them. Applicability PrIMe can be, and has been, successfully applied to several distinct applications. Notably an organ transplant management application, an aerospace engineering application and a bioinformatics application.Structure of PrIMe
The overall structure of PrIMe is shown in Figure 1. Each oval in the diagram corresponds to a distinct step within the methodology and the lines between each step indicate how they are related. The dashed ovals delimit three different phases of the methodology, comprising: (i) the identification of provenance use cases and the pieces of information that will be used to answer them, (ii) the decomposition of the application into a set of actors and their interactions and, (iii) applying a set of principled adaptations to the application in order to ensure the required information items are available for documentation. Traversing these steps, PrIMe starts from the application itself. PrIMe assumes that the structure and purpose of the application is known beforehand. This does not mean that the application must already exist, but that the overall functionality of the application has been identified and the general structure has been determined. Given this assumption, the steps through PrIMe are as follows. Phase 1- Step 1.1: Provenance use case analysis.
- Step 1.2: Identify use case information items.
- Step 2.1: Identify application actors.
- Step 2.2: Map out actor interactions.
- Step 2.3: Identify knowledgeable actors.
- Step 3.1: Introduce application adaptations.
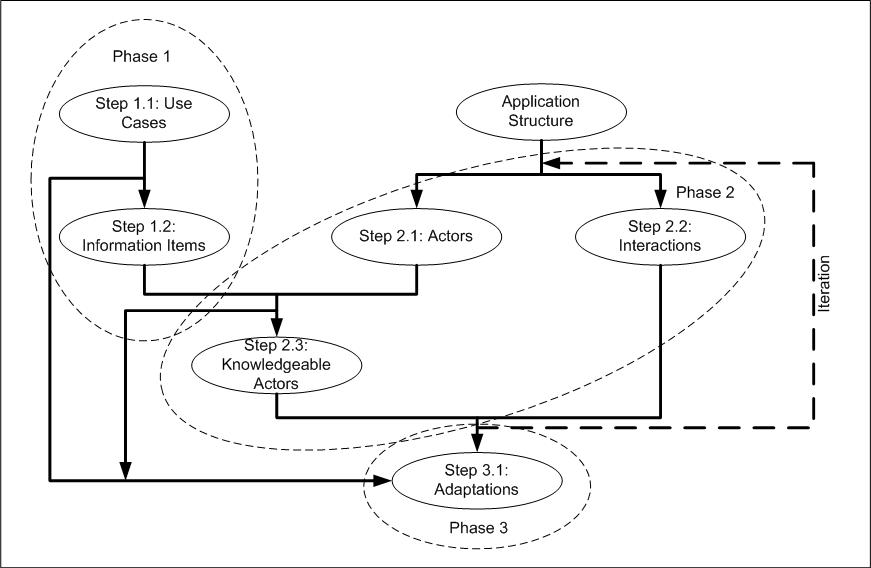 Figure 1. The Structure of PrIMe
Figure 1. The Structure of PrIMe
Key Concepts in PrIMe
PrIMe employs several key concepts, which we describe briefly belowProvenance use case questions
In Phase 1 of PrIMe, the kinds of provenance related questions to be answered about the application must be identified. These provenance use case questions determine how PrIMe will be applied by highlighting which parts of execution needs to be documented and subsequently which parts of the application must be made provenance aware. Use cases in this sense are similar to those found in UML, i.e. descriptions of scenarios in which users interact with an application. They drive the process of making an application provenance-aware by informing application developers of the granularity of the processes to be considered and the critical information to expose. Some examples of generalised use case question are listed below.- What are the details of the process that produced this result?
- Two processes, thought to be performing the same steps on the same inputs, have been run and produced different results. Was this because of a change in the inputs, the steps making up the process or the configuration of the process?
- Did the process that produced this result use the correct types of data at each stage?
- Did the process that produced this result follow the original plan?
- Did the process that produced this result meet with regulatory rules?
- What actions were this data used in performing and what actions were performed on this data?
- What were the settings/configuration of the services/tools/machines used in the process that produced this result?
- Where data is collated from multiple processes, what were the processes that fed into the process that produced this result?
- Which of these processes resulted in a satisfactory conclusion (by some criteria)?
Information items
When considering how to answer a use case, it is necessary to identify the information items that would provide answers; there may be many such items, e.g., a given result, or a sequence of decisions.- For each core provenance use case, identify the information items (pieces of information) required in order to satisfy the use case.
- For each process in the system, identify the additional items of information that could be exposed and may be useful in future provenance use cases.
Actors
Once information items have been identified, it is necessary to associate every information item with a particular component within the application. To achieve this, PrIMe decomposes the application into a set of actors and performs an analysis of their interactions. This approach is similar in nature to object oriented approaches to modelling systems, which decompose applications into classes and objects. Decomposing an application into actors follows an iterative approach, comprising the following three steps. Step 2.1: Identify an initial set of application actors. Step 2.2: Map out the interactions between these actors. Step 2.3: Identify those actors that have access to the identified information items. These steps may need to be repeated if it is discovered that no actor can be identified at the current level of granularity that has access to a use case related information item Some key points regarding actors are as follwos.- An actor is an entity within the application that performs actions, e.g. Web Services, components, machines, people etc. and interacts with other actors.
- One actor may be seen as being composed of other actors.
- A primitive actor is one for which the designers do not know the other actors of which it is composed (or do, but the decomposition is deemed to be too detailed to be relevant).
- A role is a place-holder for an actor performing a particular function, where we cannot know exactly which actor will perform that function during the application's execution.
- Roles can be composite or primitive as with actors.
Knowledgeable Actors
Any actor that has access to an information item is known as a knowledgeable actor and, as stated above, the aim is to associate every information item necessary to answer a use case question with such an actor. Some key points about knowledeable actors are as follows.- A knowledgeable actor is an actor that has access to an information item
- The primary knowledgeable actor for an information item is the primitive actor who first becomes aware of that information, which will be because:
- the actor creates the item, or
- the actor receives or observes the item from outside the application, or
- the item is a subjective assertion about another information item, e.g. a declaration that a message was received from another actor
Adaptations
PrIMe provides several application adaptations that can be used to reveal information items that are currently inaccessible, and to provide modifications to actors to enable them to record process documentation. The adaptations involve the following.- Adaptations are changes made to the flow of information in the application to ultimately expose information items to the clients who will use the documentation of process at query time.
- Many adaptations cause a new actor to become knowledgeable about an information item
- Each adaptation requires a change in the application design, and many of these make use of the components of the provenance architecture
Conclusion
PrIMe provides a step-by-step guide to making applications provenance-aware, and is vital to the development of provenance-aware applications. Application developers and users will only consider making their applications provenance-aware if they can see a clear and easy way to modify their applications to provide this functionality. Any development is a trade off between the effort and resources required to effect the development and the gains to be made by doing so. The availability of PrIMe for developers and users of applications helps to ensure that the effort required to make applications provenance-aware is minimised. 2006- Steve Munroe, Simon Miles, Victor Tan, Paul Groth, Sheng Jiang, Luc Moreau, and John Ibbotson, and Javier Vázquez-Salceda. PrIMe: A Methodology for Developing Provenance-Aware Applications. Technical report, University of Southampton, 2006. [WWW ]

![]()
to top
Edit | Attach image or document | Printable version | Raw text | More topic actions
Revisions: | r1.8 | > | r1.7 | > | r1.6 | Total page history | Backlinks
Revisions: | r1.8 | > | r1.7 | > | r1.6 | Total page history | Backlinks
SotonProvenance.PrIMeMethodologyPage moved from Restricted.PrIMeMethodologyPage on 08 Sep 2006 - 11:11 by SteveMunroe - put it back