Saturday, December 16. 2006
Central versus Distributed Archives
On Fri, 15 Dec 2006, Heather Morrison wrote in the American Scientist Open Access Forum:
The year 2006 is hence not the one in which to fete this as "very healthy" growth -- unless we want to wait till doomsday to reach 100% OA.
At this rate, Ebs Hilf estimates that it would take till 2050 to reach 100% OA in Physics. And that is without mentioning that Arxiv-style central self-archiving has not yet caught on in any other field (except possibly economics) since 1991. In contrast, distributed self-archiving in, for example, computer science, has already long overtaken Arxiv-style central self-archiving. See Citeseer (a harvester of locally self-archived papers in computer science, already twice the size of Arxiv):
Logic alone should alert us that ever since Institutional IRs and Central CRs became completely equivalent and interoperable, and seamlessly harvestable and integrable, with the OAI protocol of 1999, the days of CRs were numbered.
It makes no sense for institutional researchers either to deposit only in a CR instead of their own IR, or to double-deposit (in their own IR plus CRs, such as PubMed Central). The direct deposits will be in the natural locus, the researcher's own IR. And then CRs will harvest, as Citeseer, OAister -- and, for that matter, Google and Google Scholar -- do.
OA self-archiving is meant to be done in the interests of the impact, visibility, and recording of each institution's research output. Institutional self-archiving tiles all of OA space (whereas CRs would have to criss-cross all disciplines, willy-nilly, redundantly, and arbitrarily).
Most important, institutions, being the primary research providers, have the most direct stake in maximising -- and the most direct means of monitoring -- the self-archiving of their own research output. Hence institutional self-archiving mandates -- reinforced by research funder self-archiving mandates -- will see to it that institutional research output is deposited in its natural, optimal locus: each institution's own IR (twinned and mirrored for redundancy and preservation). CRs (subject-based, multi-subject, national, or any other combination that might be judged useful) can then harvest from the distributed network of IRs.
American Scientist Open Access Forum
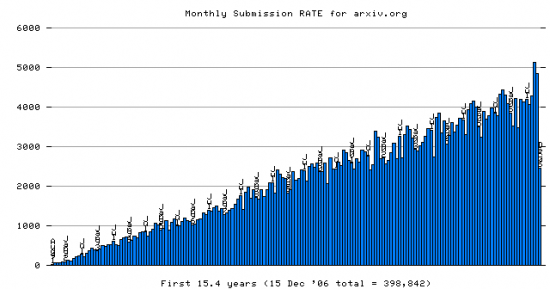
Arxiv has been showing this same, steady, unswerving linear increase in the number of deposits per month (quadratic acceleration of the total content) since the year 1991, and Arxiv has been tracking its own growth, monthly, since then.HM:"arXiv is showing very healthy growth, around 20% annually. I've been tracking arXiv on a quarterly basis, starting Dec. 31, 2005: [here]."
The year 2006 is hence not the one in which to fete this as "very healthy" growth -- unless we want to wait till doomsday to reach 100% OA.
At this rate, Ebs Hilf estimates that it would take till 2050 to reach 100% OA in Physics. And that is without mentioning that Arxiv-style central self-archiving has not yet caught on in any other field (except possibly economics) since 1991. In contrast, distributed self-archiving in, for example, computer science, has already long overtaken Arxiv-style central self-archiving. See Citeseer (a harvester of locally self-archived papers in computer science, already twice the size of Arxiv):
Logic alone should alert us that ever since Institutional IRs and Central CRs became completely equivalent and interoperable, and seamlessly harvestable and integrable, with the OAI protocol of 1999, the days of CRs were numbered.
It makes no sense for institutional researchers either to deposit only in a CR instead of their own IR, or to double-deposit (in their own IR plus CRs, such as PubMed Central). The direct deposits will be in the natural locus, the researcher's own IR. And then CRs will harvest, as Citeseer, OAister -- and, for that matter, Google and Google Scholar -- do.
OA self-archiving is meant to be done in the interests of the impact, visibility, and recording of each institution's research output. Institutional self-archiving tiles all of OA space (whereas CRs would have to criss-cross all disciplines, willy-nilly, redundantly, and arbitrarily).
Most important, institutions, being the primary research providers, have the most direct stake in maximising -- and the most direct means of monitoring -- the self-archiving of their own research output. Hence institutional self-archiving mandates -- reinforced by research funder self-archiving mandates -- will see to it that institutional research output is deposited in its natural, optimal locus: each institution's own IR (twinned and mirrored for redundancy and preservation). CRs (subject-based, multi-subject, national, or any other combination that might be judged useful) can then harvest from the distributed network of IRs.
- "Central vs. Distributed Archives" (began Jun 1999)Stevan Harnad
- "PubMed and self-archiving" (began Aug 2003)
- "Central versus institutional self-archiving" (began Nov 2003)
- "Harold Varmus: 'Self-Archiving is Not Open Access'" (began June 2006)
- Optimizing OA - Self-Archiving Mandates: What? Where? When? Why? How?
- Plugging the Loopholes in the Proposed FRPAA, RCUK and EU Self-Archiving Mandates
- Generic Rationale and Model for University Open Access Self-Archiving Mandate: Immediate-Deposit/Optional Access (ID/OA)
Swan, A., Needham, P., Probets, S., Muir, A., Oppenheim, C., O'Brien, A., Hardy, R., Rowland, F. and Brown, S. (2005) Developing a model for e-prints and open access journal content in UK further and higher education. Learned Publishing 18(1) pp. 25-40.ABSTRACT:A study carried out for the UK Joint Information Systems Committee examined models for the provision of access to material in institutional and subject-based archives and in open access journals. Their relative merits were considered, addressing not only technical concerns but also how e-print provision (by authors) can be achieved ? an essential factor for an effective e-print delivery service (for users). A "harvesting" model is recommended, where the metadata of articles deposited in distributed archives are harvested, stored and enhanced by a national service. This model has major advantages over the alternatives of a national centralized service or a completely decentralized one. Options for the implementation of a service based on the harvesting model are presented.
American Scientist Open Access Forum
EnablingOpenScholarship (EOS)
Alliance for Taxpayer Access (ATA)

Quicksearch
Syndicate This Blog


Materials You Are Invited To Use To Promote OA Self-Archiving:
Videos:
audio WOS
Wizards of OA -
audio U Indiana
Scientometrics -
The American Scientist Open Access Forum has been chronicling and often directing the course of progress in providing Open Access to Universities' Peer-Reviewed Research Articles since its inception in the US in 1998 by the American Scientist, published by the Sigma Xi Society.
The American Scientist Open Access Forum has been chronicling and often directing the course of progress in providing Open Access to Universities' Peer-Reviewed Research Articles since its inception in the US in 1998 by the American Scientist, published by the Sigma Xi Society.
The Forum is largely for policy-makers at universities, research institutions and research funding agencies worldwide who are interested in institutional Open Acess Provision policy. (It is not a general discussion group for serials, pricing or publishing issues: it is specifically focussed on institutional Open Acess policy.)
You can sign on to the Forum here.
Archives
Calendar
Categories
Blog Administration
Statistics
Last entry: 2018-09-14 13:27
1129 entries written
238 comments have been made